이 글은 네이버 블로그 유하님과 인터넷 크롤링을 통한 정보들을 바탕으로 작성되었습니다.
음성을 연구할 때 중요한 것은 소리이며, 철자는 무시한다. 오직 음에만 집중함
The Difference between Spelling and Sound
- 알파벳은 26개, 하지만 소리는 43-44개 정도임
- 철자가 소리를 모두 나타내지 못함
- 각각의 문자를 graphemes라고 함
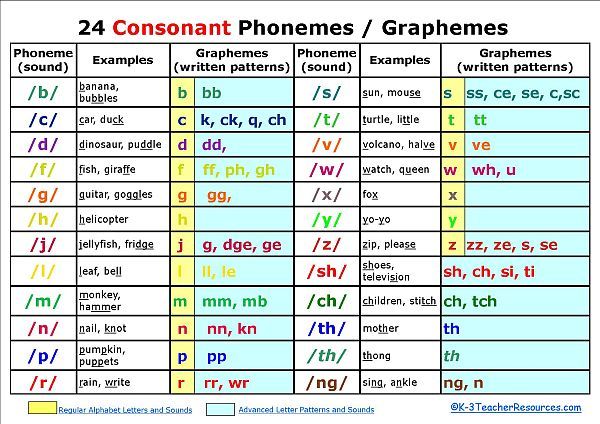
e.g., thorugh: t-h-r-o-u-g-h --> 총 7개의 graphemes, 하지만 sound는 ‘th-r-u’ 3개
e.g., phlegm: p-h-l-e-g-m --> 총 6개의 graphemes, 하지만 sound는 ‘f-l-e-m’ 4개
- Graphemes는 단지 스펠링만 알려줄 뿐, 실제 pronounce에는 어떠한 단서도 제공하지 않음
- 그리고 graphemes는 그들이 가진 sound를 정확하게 나타내지 못함
e.g., grphemes의 ‘s’ --> size /s/, vision /z/
==> 같은 문자가 서로 다른 소리를 갖음
Phonetic Alphabet

- 개별적 소리에 대해 개별적 문자를 갖으면서 소리와 문자가 서로 1:1 관계를 이룸
- Roman Alphabet은 26개로 43-44개의 소리를 적절히 나타내기 때문에 하나의 알파벳이 여러 개의 소리를 갖음
Allographs (이문자)
- 위와는 반대로, 소리는 같은데 다른 문자를 가지기도 함
e.g., loop, through, threw, fruit, canoe
Digraphs
- 같은 문자가 2개, 또는 완전 다른 문자가 2개씩 짝을 이루는 것을 말함
e.g., hoot, heed, tissue, shoe, steak, tried
Silent letters

- 소리를 내지 않는 grapheme임
e.g., p-l-u-m-b: 5개의 문자, p-l-u-m: 4개의 소리, ==> ‘b’ = silent letter
- chord, psychosis, flea, pneumonia ==> 주로 차용어들이 대상임
이는 단어 기원과 관련이 있음
- 차용어들을 글자 그대로 간직하여 받아들이나, 소리는 영어의 소리 체계에 맞게 발음하는 것
Duration (소리의 길이)
- 소리가 발음되는 동안의 길이
e.g., through, reamins, snowman, awakens ==> 모두 똑같이 7개의 grphemes으로 이루어져 있지만, 발음되는 길이는 각각 다름
e.g., gum, thought, what, straight ==> grapheme은 각각 다르지만, 발음되는 길이가 모두 같음
Morphemes (형태소)

- 유사한 의미적(뜻) 언어 단위
- 즉, 가장 작은 의미를 가질 수 있는 언어의 최소 단위
e.g., book: ‘책’이라는 의미를 갖는 하나의 형태소
e.g., books: 복수의 의미를 가지고 있기에 하나의 형태소로 인정함, 즉 두 개의 형태소를 갖고 있음
walked(과거), calling(명사형), prepaid(앞서, 미리라는 의미의 접두사), reread(다시라는 의미의 접두사), construction(명사 만드는 접미사), talkative(성질을 나타내는 형용사) ==> 모두 의미를 가지고 있으므로 형태소임
- 같은 형태소를 공유할지라도 발음의 변화가 생길 수 있음
e.g., music /k/ -> musician /s/, phlegm /무음/ -> phlegmatic /g/, press /s/ -> pressure /\/
- 형태소는 2가지로 나뉨
Free morpheme
- 홀로 쓰일 수 있으며 독자적인 의미를 갖음
e.g., book, phlegm, candy, love ...
- Bound morpheme
홀로 쓰일 수 없으며, 독자적인 의미를 갖지 못함
e.g., -s, -ed, -ian, predate, retread ...
Phoneme (음소)
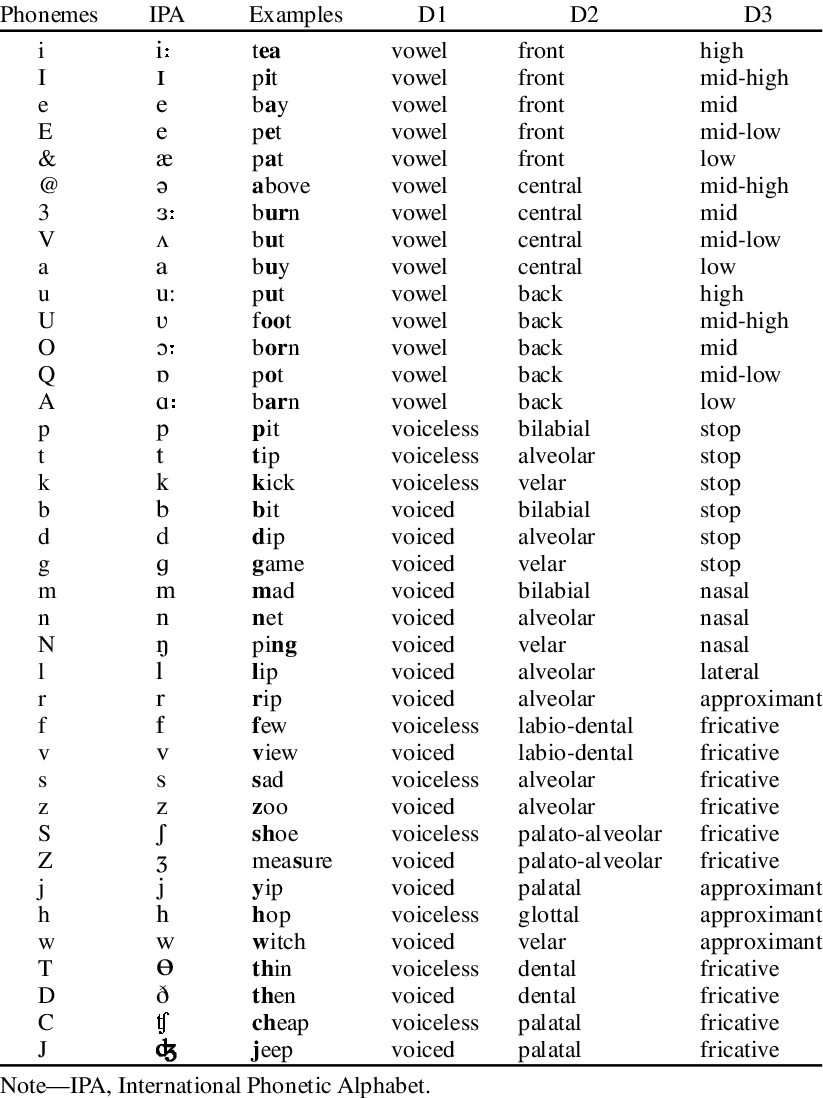
- 뜻의 차이를 가져오는 최소의 단위
1886년, IPA창립, 말을 기록하기 위해 채택되어짐
- 음소는 형태소에 차이를 줄 수 있는 어떠한 음
IPA는 음성적 알파벳, 각각의 표기는 특정한 음소 또는 소리를 나타냄
- 음소가 바뀌면 그 의미도 달라짐
e.g., book -> cook: 한 음소의 변화는 형태소의 의미를 바꾸게 됨
- 이처럼 단어의 오직 한 음소만 바꾸어 의미 차이를 갖는 것을 minimal pair (최소대립쌍)이라고 함
- 이는 음소를 확인하는 중요한 방법으로 작용함
e.g., hear/beer, cat/cab ...
Allophones (이음)
- 음소 가족의 구성원
- 음소는 소리들의 기록으로 모든 단어에서 같은 발음으로 나지 않음
e.g., /l/ in ‘lip’, ‘ball’
‘lip’ 의 /l/: 혀가 입 천장에서 닿으며 소리 남
‘ball’의 /l/: 혀 뒤쪽에서 수축되어 소리가 남. 하지만 /l/을 어떻게 발음하든 간에, 의미 변화는 생기지 않음
==> 이처럼 다양한 발음을 allophone이라고 하며, 이 역시 음소를 확인하는 중요한 방법으로 작용함
Complementary distribution (상보적 분포)
- 이음은 같은 장소에서 동시에 나타날 수 없음
즉 ‘lip’의 /l/과 ‘ball’의 /l/은 각각의 음성적 제약으로 인해 서로 바뀔 수 없는데 이를 상보적 분포에 있다 라고 함
- 상보적 분포에 존재하는 음들은 이음이고, 그러지 않은 음들은 음소로 구분 됨
그래서 상보적 분포 역시 음소를 확인하는 방법으로 작용함
Free variation (자유변이)
e.g., keep의 /p/: ‘키프’라고 세게 발음하든 ‘킾’이라고 약하게 발음하든 의미는 달라지지 않음
이러한 관계를 자유변이라고 함
'Signal, Speech Processing > Phonetics' 카테고리의 다른 글
| Vowel Transcription - Five back vowels (0) | 2020.02.10 |
|---|---|
| Vowel Transcription - Five front vowels (0) | 2020.02.10 |
| Anatomy of the Speech Mechanism (0) | 2020.02.10 |
| Phonemes, Syllables notation methods (0) | 2020.02.10 |
| Phonetics (0) | 2020.02.10 |











