import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.autograd import Variable
import os
import matplotlib.pyplot as plt
import numpy as np
torch.__version__
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
torch.manual_seed(2891)
num_gpu = 1
if torch.cuda.device_count() > 1:
num_gpu = torch.cuda.device_count()
print("Let's use", num_gpu, "GPUs!")
print('our device', device)
'''
Let's use 1 GPUs!
our device cuda
'''
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
model_hp = count_parameters(model)
print('model"s hyper parameters', model_hp)
# model"s hyper parameters 374026
Dataset load, train, test loader 선언
train_loader = torch.utils.data.DataLoader(datasets.MNIST('data', train=True, download=True, transform=transforms.ToTensor()),batch_size=batch_size, shuffle=True)
print(len(train_loader)) # 600
test_loader = torch.utils.data.DataLoader(datasets.MNIST('data', train=False, transform=transforms.ToTensor()),batch_size=1000)
print(len(test_loader)) # 10
'''
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz to data/MNIST/raw/train-images-idx3-ubyte.gz
9913344/? [04:53<00:00, 33768.69it/s]
Extracting data/MNIST/raw/train-images-idx3-ubyte.gz to data/MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz to data/MNIST/raw/train-labels-idx1-ubyte.gz
29696/? [00:00<00:00, 433940.88it/s]
Extracting data/MNIST/raw/train-labels-idx1-ubyte.gz to data/MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz to data/MNIST/raw/t10k-images-idx3-ubyte.gz
1649664/? [00:51<00:00, 32232.92it/s]
Extracting data/MNIST/raw/t10k-images-idx3-ubyte.gz to data/MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz to data/MNIST/raw/t10k-labels-idx1-ubyte.gz
5120/? [00:00<00:00, 108088.65it/s]
Extracting data/MNIST/raw/t10k-labels-idx1-ubyte.gz to data/MNIST/raw
Processing...
Done!
600
10
/usr/local/lib/python3.7/dist-packages/torchvision/datasets/mnist.py:502: UserWarning: The given NumPy array is not writeable, and PyTorch does not support non-writeable tensors. This means you can write to the underlying (supposedly non-writeable) NumPy array using the tensor. You may want to copy the array to protect its data or make it writeable before converting it to a tensor. This type of warning will be suppressed for the rest of this program. (Triggered internally at /pytorch/torch/csrc/utils/tensor_numpy.cpp:143.)
return torch.from_numpy(parsed.astype(m[2], copy=False)).view(*s)
'''
Loss, optimizer 선언
이전에는 F.nll_loss로 하였는데, 이번에는 CrossEntropy loss를 선언하여 진행함
이번에는 이전 post와 같은 MNIST dataset을 활용하여, CNN으로 성능 뽑는것을 진행해본다.
CNN은 Fully-connected layer와 달리 flatten을 해줄 필요가 없어서 parameter가 비교적 적게 들고, 연산이 빠른 장점이 있으며, receptive field를 통해 local feature를 뽑는 것에 강인한 특징이 있음
Library importing 및 device 설정
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.autograd import Variable
import os
import matplotlib.pyplot as plt
import numpy as np
torch.__version__
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
torch.manual_seed(2891)
num_gpu = 1
if torch.cuda.device_count() > 1:
num_gpu = torch.cuda.device_count()
print("Let's use", num_gpu, "GPUs!")
print('our device', device)
'''
Let's use 1 GPUs!
our device cuda
'''
2-layer CNN 네트워크 설계 (add here 부분에 batchnormalization, 더 깊게 쌓는 것들을 연습해보세요)
class CNN(nn.Module):
def __init__(self, num_class, drop_prob):
super(CNN, self).__init__()
# input is 28x28
# padding=2 for same padding
self.conv1 = nn.Conv2d(1, 32, 5, padding=2) #input_channel, output_channel, filter_size, padding_size, (kernel=omit)
# feature map size is 14*14 by pooling
# padding=2 for same padding
self.conv2 = nn.Conv2d(32, 64, 5, padding=2)
# feature map size is 7*7 by pooling
'''
add here.. make more deep...
batchnormalization ++
'''
self.dropout = nn.Dropout(p=drop_prob)
self.fc1 = nn.Linear(64*7*7, 1024)
self.reduce_layer = nn.Linear(1024, num_class)
self.log_softmax = nn.LogSoftmax(dim=1)
def forward(self, x):
x = F.max_pool2d(F.relu(self.conv1(x)), 2) # -> (B, 14, 14, 32)
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
'''
add here.. make more deep...
and use dropout
'''
x = x.view(-1, 64*7*7) # reshape Variable for using Linear (because linear only permit 1D. So we call this task as "flatten")
x = F.relu(self.fc1(x))
output = self.reduce_layer(x)
return self.log_softmax(output)
#model shape
for p in model.parameters():
print(p.size())
'''
torch.Size([32, 1, 5, 5])
torch.Size([32])
torch.Size([64, 32, 5, 5])
torch.Size([64])
torch.Size([1024, 3136])
torch.Size([1024])
torch.Size([10, 1024])
torch.Size([10])
'''
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
model_hp = count_parameters(model)
print('model"s hyper parameters', model_hp)
# model"s hyper parameters 3274634
Data setup 및 train, test loader 설정
batch_size = 64
train_loader = torch.utils.data.DataLoader(datasets.MNIST('data', train=True, download=True, transform=transforms.ToTensor()),batch_size=batch_size, shuffle=True)
print(len(train_loader)) # 938, 64 * 938 = 60032
test_loader = torch.utils.data.DataLoader(datasets.MNIST('data', train=False, transform=transforms.ToTensor()),batch_size=1000)
print(len(test_loader)) # 10, (10 * 1000 = 10000)
'''
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz to data/MNIST/raw/train-images-idx3-ubyte.gz
9913344/? [04:51<00:00, 34050.71it/s]
Extracting data/MNIST/raw/train-images-idx3-ubyte.gz to data/MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz to data/MNIST/raw/train-labels-idx1-ubyte.gz
29696/? [00:01<00:00, 26930.77it/s]
Extracting data/MNIST/raw/train-labels-idx1-ubyte.gz to data/MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz to data/MNIST/raw/t10k-images-idx3-ubyte.gz
Failed to download (trying next):
HTTP Error 503: Service Unavailable
Downloading https://ossci-datasets.s3.amazonaws.com/mnist/t10k-images-idx3-ubyte.gz
Downloading https://ossci-datasets.s3.amazonaws.com/mnist/t10k-images-idx3-ubyte.gz to data/MNIST/raw/t10k-images-idx3-ubyte.gz
1649664/? [00:00<00:00, 3989386.71it/s]
Extracting data/MNIST/raw/t10k-images-idx3-ubyte.gz to data/MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz to data/MNIST/raw/t10k-labels-idx1-ubyte.gz
Failed to download (trying next):
HTTP Error 503: Service Unavailable
Downloading https://ossci-datasets.s3.amazonaws.com/mnist/t10k-labels-idx1-ubyte.gz
Downloading https://ossci-datasets.s3.amazonaws.com/mnist/t10k-labels-idx1-ubyte.gz to data/MNIST/raw/t10k-labels-idx1-ubyte.gz
5120/? [00:00<00:00, 139107.35it/s]
Extracting data/MNIST/raw/t10k-labels-idx1-ubyte.gz to data/MNIST/raw
Processing...
Done!
938
10
/usr/local/lib/python3.7/dist-packages/torchvision/datasets/mnist.py:502: UserWarning: The given NumPy array is not writeable, and PyTorch does not support non-writeable tensors. This means you can write to the underlying (supposedly non-writeable) NumPy array using the tensor. You may want to copy the array to protect its data or make it writeable before converting it to a tensor. This type of warning will be suppressed for the rest of this program. (Triggered internally at /pytorch/torch/csrc/utils/tensor_numpy.cpp:143.)
return torch.from_numpy(parsed.astype(m[2], copy=False)).view(*s)
'''
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.autograd import Variable
import os
import matplotlib.pyplot as plt
import numpy as np
또한 아래의 코드를 통해 현재의 pytorch 버전에 대해 확인함
torch.__version__
이후 연산할 장치에 대해 선언해야 함
아래와 같이 device를 gpu로 설정함
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
torch.manual_seed(2891)
num_gpu = 1
if torch.cuda.device_count() > 1:
num_gpu = torch.cuda.device_count()
print("Let's use", num_gpu, "GPUs!") # 1
print('device', device) # cuda
이후 간단한 MLP (Multi-Layer Perceptron) 모델을 구현함
입력은 MNIST dataset을 사용함
MNIST dataset의 각각의 요소는 (28, 28) 의 shape을 갖고 있기 때문에,
MNIST의 class 개수는 10개 이므로, 첫 번째 인자에 10을 넣었고, dropout은 30%확률로 진행
작성한 모델의 매 layer 마다의 shape은 아래를 통해서 확인할 수 있고,
#model shape
for p in model.parameters():
print(p.size())
'''
torch.Size([512, 784])
torch.Size([512])
torch.Size([256, 512])
torch.Size([256])
torch.Size([10, 256])
torch.Size([10])
torch.Size([10, 10])
torch.Size([10])
'''
총 hyperparameter는 아래를 통해 확인 가능함
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
model_hp = count_parameters(model)
print('model"s hyper parameters', model_hp)
'''
model"s hyper parameters 535928
'''
이제 모델 선언은 끝났고, data를 loading 해야 함
아래의 코드를 통해 MNIST dataset을 다운받고, train 및 test로 분할함
batch_size = 128
train_loader = torch.utils.data.DataLoader(datasets.MNIST('data', train=True, download=True, transform=transforms.ToTensor()),batch_size=batch_size, shuffle=True)
print(len(train_loader)) # 118, 512 * 118 = 60000
test_loader = torch.utils.data.DataLoader(datasets.MNIST('data', train=False, transform=transforms.ToTensor()),batch_size=1000)
print(len(test_loader)) # 10, 10 * 1000 = 10000
'''
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz to data/MNIST/raw/train-images-idx3-ubyte.gz
9913344/? [04:54<00:00, 33670.03it/s]
Extracting data/MNIST/raw/train-images-idx3-ubyte.gz to data/MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz to data/MNIST/raw/train-labels-idx1-ubyte.gz
29696/? [00:01<00:00, 26891.25it/s]
Extracting data/MNIST/raw/train-labels-idx1-ubyte.gz to data/MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz to data/MNIST/raw/t10k-images-idx3-ubyte.gz
Failed to download (trying next):
HTTP Error 503: Service Unavailable
Downloading https://ossci-datasets.s3.amazonaws.com/mnist/t10k-images-idx3-ubyte.gz
Downloading https://ossci-datasets.s3.amazonaws.com/mnist/t10k-images-idx3-ubyte.gz to data/MNIST/raw/t10k-images-idx3-ubyte.gz
1649664/? [00:00<00:00, 3911534.90it/s]
Extracting data/MNIST/raw/t10k-images-idx3-ubyte.gz to data/MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz to data/MNIST/raw/t10k-labels-idx1-ubyte.gz
5120/? [00:00<00:00, 159181.34it/s]
Extracting data/MNIST/raw/t10k-labels-idx1-ubyte.gz to data/MNIST/raw
Processing...
Done!
469
10
/usr/local/lib/python3.7/dist-packages/torchvision/datasets/mnist.py:502: UserWarning: The given NumPy array is not writeable, and PyTorch does not support non-writeable tensors. This means you can write to the underlying (supposedly non-writeable) NumPy array using the tensor. You may want to copy the array to protect its data or make it writeable before converting it to a tensor. This type of warning will be suppressed for the rest of this program. (Triggered internally at /pytorch/torch/csrc/utils/tensor_numpy.cpp:143.)
return torch.from_numpy(parsed.astype(m[2], copy=False)).view(*s)
'''
Optimizer 선언은 아래와 같이 진행하며, 가장 많이 사용되는 Adam을 learning rate 1e-4로 사용
Batch_size에 따라, 혹은 미리 데이터를 전처리 할 때, sequential 한 데이터셋에 대해 maximum length를 구해야 할 때가 있다.
이후에 Zero padding 까지 해주어야 하는데, 이번 글에서는 maximum length 구하는 것만 다룬다.
아주 직관적이고 쉬운 코드로 가겠다.
import numpy as np
a = np.random.rand(1, 7)
b = np.random.rand(1, 20)
c = np.random.rand(1, 3)
d = np.random.rand(1, 50)
print('a {}, a shape {}'.format(a, a.shape))
print('b {}, b shape {}'.format(b, b.shape))
print('c {}, c shape {}'.format(c, c.shape))
print('d {}, d shape {}'.format(d, d.shape))
dataset = list()
dataset.append(a)
dataset.append(b)
dataset.append(c)
dataset.append(d)
2차원 데이터에 대해, 예를 들어 text 라고 가정하겠다. ['안', '녕', '하', '세', '요'] 라고 되어 있는 데이터셋은 (1,5)의 shape을 갖는다. 이 데이터셋들을 전체로 모아서 처리할 땐 glob 등을 사용하지만, 예시에서는 4개를 임의로 세팅하고 dataset.append 을 이용하여 7, 20, 3, 50의 길이를 갖는 데이터셋을 임의적으로 만들었다.
def target_length_(p):
return len(p[0])
length = list()
for i in range(len(dataset)):
i_th_len = target_length_(dataset[i]) # return length
length.append(i_th_len)
max_length = np.argmax(length) # find maximum length
print(max_length) # max_length index
maximum_length = length[max_length]
print(maximum_length)
그 뒤, 데이터셋을 매 번 반복하여 위의 target_length_ 함수를 이용해서 원하는 차원의 length를 구하면 된다.
2차원, 3차원, 4차원 등 원하는대로 설정하여 maximum length 값을 얻어 올 수 있다.
import numpy as np
a = np.random.rand(1, 7)
b = np.random.rand(1, 20)
c = np.random.rand(1, 3)
d = np.random.rand(1, 50)
print('a {}, a shape {}'.format(a, a.shape))
print('b {}, b shape {}'.format(b, b.shape))
print('c {}, c shape {}'.format(c, c.shape))
print('d {}, d shape {}'.format(d, d.shape))
dataset = list()
dataset.append(a)
dataset.append(b)
dataset.append(c)
dataset.append(d)
def target_length_(p):
return len(p[0])
length = list()
for i in range(len(dataset)):
i_th_len = target_length_(dataset[i]) # return length
length.append(i_th_len)
max_length = np.argmax(length) # find maximum length
print(max_length) # max_length index
maximum_length = length[max_length]
print(maximum_length)
Tensorflow는 pytorch의 dataloader처럼 queue를 사용하여, 전체 데이터셋을 가져온 뒤 그것을 batch 만큼 쪼개서 하는 것이 살짝 번거롭다.
즉 이말을 다시 풀어보면, pytorch에서는 dataloader를 사용하여 여러 queue를 사용해서 batch 만큼 데이터셋을 가져온 뒤, 이것을 tensor로 바꿔서 model에 넣는 것이 수월한데 비해
Tensorflow에서는 tf.data.Dataset.from_tensor_slices 를 사용해서 전체 데이터셋을 가져오는 예제가 많다.
게다가 대용량 데이터셋을 사용하게 될 경우, 데이터셋의 총 사이즈가 3GB 정도가 넘어가면 tensorflow 는 API 관련 오류가 생기면서 data load가 안 될 때가 있다.
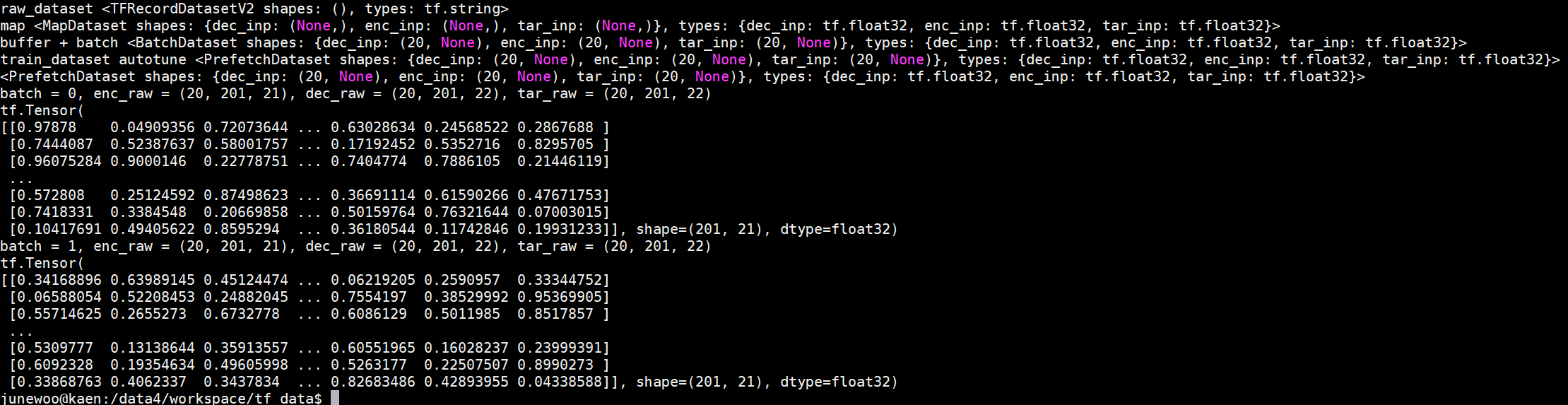
근 3일 정도 고생하면서 찾아본 정보들을 합쳐서, 음성 데이터셋의 stft 한 결과인 2차원 데이터셋을 tfrecord로 저장하는 방법을 소개한다.
# 전처리
음성(.wav)파일 모두에 대해, 2차원 stft를 얻었다고 가정하고 진행하겠다.
stft를 바꾸는 방법은 이 블로그 내에 있다.
import tensorflow as tf
print(tf.__version__)
import os
import librosa
from glob import glob
import numpy as np
list_inp = sorted(glob('/your/input/dataset/*/*.npz'))
list_tar = sorted(glob('/your/target/dataset/*/*.npz'))
print(len(list_inp))
위의 코드는 모든 음성 파일을 .npz 라는 numpy 형태의 data format으로 미리 저장해둔 상태이고, 이것을 glob으로 가져오는 모습이다. Seq2Seq 모델의 Encoder input인 list_inp와 Decoder input, Real value input인 list_tar의 전체를 가져온다.
2d numpy 값을 그대로 value=feature1 를 해주면, 오류가 생긴다. 이를 찾아보게 되면, tensorflow에서의 FloatList는 1차원 값만 넣어줄 수 있기 때문이다. 그러므로, flatten()을 하여 넣어준다.
나 같은 경우 input과 target을 모두 maximum legnth를 구하고 zeropadding하여 shape을 아는 상태이지만, 만약 데이터셋이 모두 다를 경우 feature['shape'] = tf.train.Feature(int_list=tf.train.IntList(value=feature1.shape) 을 대입하여 나중에 데이터셋을 실제로 model에 넣을 때 shape을 기억하여 변환할 수 있다.
그다음 features = tf.train.Features(feature=feature)를 통해 tensorflow의 tensor로 변환해주고,
example 또한 마찬가지로 변환해준다.
serialized = example.SerializeToString() 을 통하여 binary? 로 변환해준다. 마지막으로 tf.records 파일을 write 해주는 writer.write(serialized)를 해주면 끝난다.
이것을 batch size만큼 해준다...
전체코드는 아래와 같다.
# 전체 코드
import tensorflow as tf
print(tf.__version__)
import os
import librosa
from glob import glob
import numpy as np
def serialize_example(batch, list1, list2):
filename = "./train_set.tfrecords"
writer = tf.io.TFRecordWriter(filename)
for i in range(batch):
feature = {}
feature1 = np.load(list1[i])
feature2 = np.load(list2[i])
print('feature1 shape {} feature2 shape {}'.format(feature1.shape, feature2.shape))
feature['input'] = tf.train.Feature(float_list=tf.train.FloatList(value=feature1.flatten()))
feature['target'] = tf.train.Feature(float_list=tf.train.FloatList(value=feature2.flatten()))
features = tf.train.Features(feature=feature)
example = tf.train.Example(features=features)
serialized = example.SerializeToString()
writer.write(serialized)
print("{}th input {} target {} finished".format(i, list1[i], list2[i]))
list_inp = sorted(glob('/your/input/dataset/*/*.npz'))
list_tar = sorted(glob('/your/target/dataset/*/*.npz'))
print(len(list_inp))
serialize_example(len(list_inp), list_inp, list_tar)
input, target 각각 8백만개 씩 있는데, 이것들이 과연 tfrecords를 통해 저장하였을 때의 공간적 이득과, 시간이 얼마나 걸리는지 체크해봐야겠다.
체크 해본 뒤, Tfrecord 파일을 다시 원래대로 음성 데이터 spectrogram으로 복구하는 것을 이번주내로 올릴 예정이다.