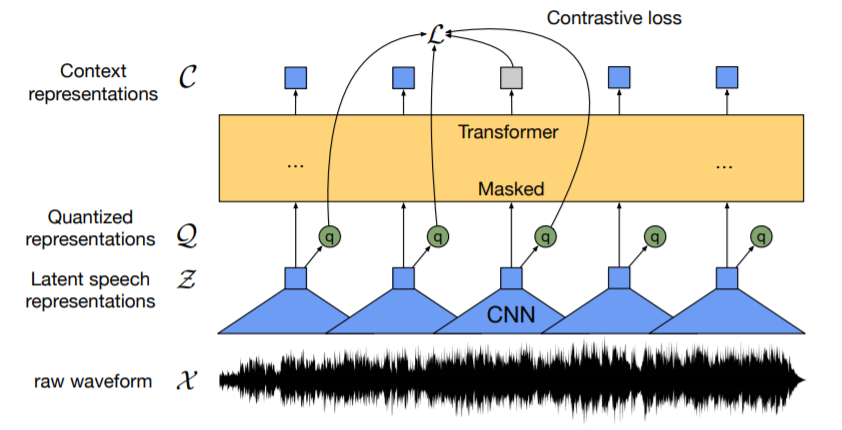
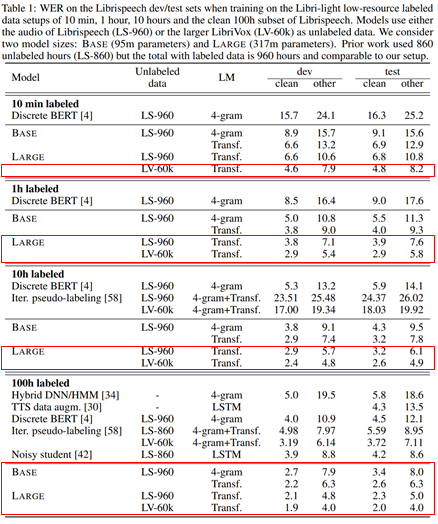
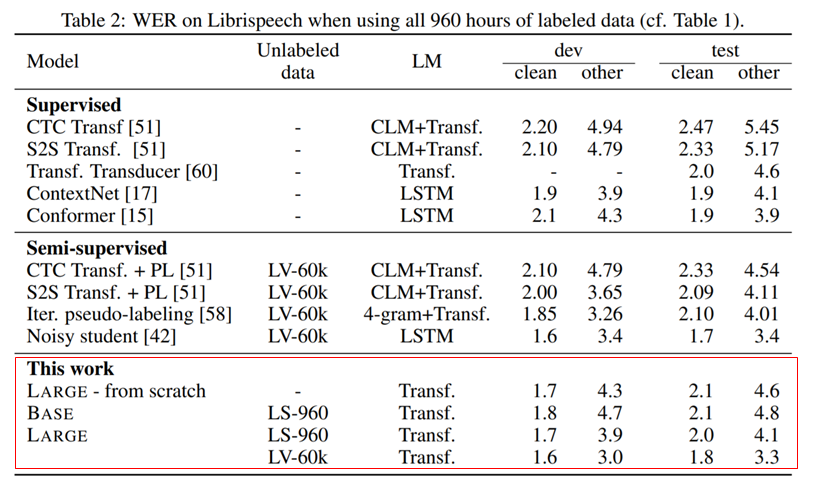
이번 논문은 Speech-XLNet: Unsupervised acoustic model pretraining for self-attention networks [1]이며, 마찬가지로 NLP에서 사용되는 XLNET [2]의 기법들을 speech recognition에 적용하였음
하지만, XLNET에서 중요시 되는 ordering, permutation, Two-stream self-attention 관련 된 부분의 설명이 너무 너무 많이 부족함
또한 github도 공개가 되어 있지 않기 때문에 실제로 해당 결과물에 대한 신뢰도가 많이 떨어지는 상태인 것을 감안하고 읽어야 하며, 개념적인 부분만 체크하기 위해 리뷰함
Overview
- XLNet과 유사한 pretraining scheme인 "Speech-XLNet" 제안
- Self-attention network (SAN)을 위한 permutation-based autoregressive (AR) acoustic model pre-training scheme 제안
- Speech-XLNet은 factorization order의 가능한 모든 permutation과 관련하여 음성 특징 시퀀스의 예상 log likelihood를 최대화 함
- Frame 순서를 셔플링함으로써 permutation은 bi-directional contextual information 및 글로벌 구조를 캡처하는데 도움이 되며, autoencoding 음향 모델링과 AR의 장점을 모두 활용하면서 단점을 피할 수 있음
Related works
1. AR 모델에 대한 제약 2가지
주변 음성 프레임
- 인접한 음성 frame은 상관 관계가 높기 때문에 이러한 local smoothness를 활용하면 이미 다음 frame을 예측하기에 충분할 수 있음
- 따라서 regularization이 없으면 pre-training 과정에서 global 구조를 포착하는데 어려움이 있을 수 있음
- AR pre-training은 또한 seq2seq 작업에 도움이 되는 bi-directional context information으로 어려움을 겪을 수 있음
2. Masking method의 단점
- Pre-training 중에 BERT에서 사용하는 0값으로 masking 된 frame은 fine-tuning process에서 사용되는 labeled 데이터에는 존재하지 않음
- 이로 인해 사전 훈련-미세 조정 불일치가 발생할 수 있음
- BERT는 non-masking frame이 주어지면 예측 된 frame이 서로 독립적이라고 가정하므로 AR 모델에서 사용되는 곱 규칙을 사용하여 joint probability distribution을 모델링 할 수 없음
3. XLNet과의 차이점
1) Next sentence prediction과 segment recurrence mechanism을 사용하지 않음
- 두 방법 모두 연속 된 문장에서 long-distance dependencies를 추출하는 데 사용됨
- 그러나 음성 인식 데이터 셋에서의 다른 발화는 일반적으로 서로 독립적이기 때문에 관계가 없음
2) Word token이 아닌 frame masking reconstruction
- Classification task에서 regression task 작업으로 XLNet 조정
3) Dynamic permutation 전략 사용
- XLNet은 데이터 전처리 중에 한 번 permutation을 수행함
- 반대로 Speech-XLNet은 음성 sequence가 trainer에 공급 될 때마다 permutation 순서를 재생성함
- 따라서 각 training의 epoch에 공급되는 모든 sequence에 대해 서로 다른 permutation을 사용하기 때문에 훈련 데이터의 양이 증가함
Proposed method
1. Model architecture
- Speech-XLNet의 encoder와 decoder는 XLNet과 Transformer와 같음
2. Proposed SAN/HMM and end-to-end SAN in the pre-training models

1) SAN/HMM
- 하이브리드 모델은 pre-training 중 아래 그림의 frame-stacking을 진행하지 않는데, 이는 downstream task에 대한 frame level의 alignment 정보를 얻어야 하기 때문임
- Frame-stacking을 하면 HMM기반의 align이 되지 않기 때문에 SAN/HMM에서는 frame-stacking을 사용하지 않음

- 위의 frame-stacking은 4개의 subsampling이 5개로 stack됨을 보임
2) SAN
- 반면 SAN은 align 정보가 필요하지 않기 때문에 pre-training 시에도 sequence length와 연산 속도를 줄여주는 frame-stacking을 사용함
3. Pre-train objective function
- XLNet과는 달리, Speech-XLNet은 다음 acoustic frame을 "예측함"
$min_\theta\mathbb{E}_{o\sim\mathcal{O}_{T}[\Sigma_{t=1}^T\mathcal{L}(o_t,\hat{y}_{t|o<t})]}$
- 여기에서 $\mathcal{O}_T$는 길이 $T$인 sequence의 가능한 모든 permutation 집합임
- $O=[o_1,o_2,...,o_T]$이고, $o_t$는 $t$번째 element이고, $o_{<t}$는 permutation $O\in\mathcal{O}_T$의 첫 번째 $t-1$요소임
- $\theta$는 parameter 집합을 나타냄
- $\hat{y}_t|o_{<t}$는 permutation 순서 $o_{<t}$의 이전 frame이 주어진 예측 프레임을 뜻함
- Permutation 된 sequence의 꼬리 부분에 있는 frame의 마지막 20% 만 예측하도록 선택함
- $T$를 시퀀스 길이로, $e$를 선택한 frame 수라 할 때, objective function을 아래와 같이 지정함
$min_\theta\mathbb{E}_{o\sim\mathcal{O}_T[\Sigma_{t=T-e+1}^T\mathcal{L}(o_t,\hat{y}_{t|o<t})]}$
4. Two-stream self-attention
- Query stream은 pre-training에서만 사용되고, fine-tuning에서는 제거됨
- 나머지 설명은 해당 논문에 없음
Experimental setups
1. Pre-processing
- Kaldi로부터 CMVN을 적용한 40-dimensional log-Mel filterbanks 사용
2. Hybrid ASR on TIMIT
1) SNN/HMM
- 8개의 attention head의 block당 6개의 self-attention block이 있음
- $d_{model}$은 512로, $d_{ffn}$은 2048로, 드롭 아웃은 0.1로, Huber 손실은 0.1로, optmizer는 Adam 사용
2) Pre-training
- LibriSpeech, TED-LIUM release2 및 WSJ-si284를 사용, 배치 크기는 6000 frame으로 할당
3) Fine-tuning
- 4000 frame의 배치 크기로 Hybrid SAN/HMM 설정에서 Cross Entropy loss로 fine-tuning
- Frame level alignment는 1936개의 senone cluster가 있는 triphone GMM/HMM과 함께 Kaldi s5 레시피를 사용하여 얻음
3. End-to-End transformer ASR on WSJ
1) Architecture
- 12개의 인코더, 6개의 디코더로 구성되어 있으며, 각기 4개의 attention head가 있음
- $d_{model}$은 256, $d_{ffn}$은 2048, Adam 사용
- Target 텍스트의 출력 알파벳은 총 32개의 classes (26 개의 대문자, 아포스트로피, 마침표, 공백, unknown token, <sos>, <eos>)
- 연속 된 3개의 프레임 stacking, 3개 sub-sampling
2) Baseline
- Fine-tuning process와 동일한 설정으로 scratch training
- Beam search는 beam size 15 및 length penalty 0.6으로 수행
3) 평가 데이터
- WSJ-si284
Results
1. PER results



- Pre-trained된 SAN은 초기 epoch에서 weight가 임의로 초기화 된 SAN보다 훨씬 빠르게 수렴
- SAN은 hyperparameter에 매우 민감하지만 proposed된 pre-trained 된 SAN의 성능은 훨씬 더 안정적임을 보임
2. Results of hybrid ASR on TIMIT

- 무작위로 초기화 된 weight로 training이 끝나면 모든 head의 attention score는 위의 그림 (c)에서 명확한 대각선 패턴을 나타내며, 이것은 현재 프레임 주변의 제한된 컨텍스트만 탐색됨을 의미함
- 그림 (d)에서 두 번째 head의 attention score는 확률 분포가 모두 대각선을 벗어나는데, 논문에서 저자들은 이는 관심 분포가 downstream task에 유용한 일부 "global"구조를 학습다고 주장함
3. Reporting WERs from 5 of settings

1) SCRATCH
- 무작위로 초기화 된 weight로 Baseline을 end-to-end 훈련
2) WSJ-Perm, LIBRI-Perm
- 81h WSJ-si284 및 960h LibriSpeech를 사용하여 Speech-XLNet으로 인코더 pre-training 이후 fine-tuning
3) WSJ-NoPerm, LIBRI-NoPerm
- Pre-training 중 permutation 폐기한 결과
- 당연히 Pre-training에서 가장 많은 데이터로 학습 된 LIBRI-PERM이 좋은 성능을 봉미
Conclusion
- NLP의 XLNet의 개념을 이용한 Speech-XLNet
하지만...
- 해당 논문의 Two-stream self-attention 부분은 page 용량 문제로 언급이 하나도 되어 있지 않음
- 그리고 기존 XLNET에 비해 마지막 20% 부분만 permutation으로 사용
- Permutation order가 어느 정도 사용 되었는지도 설명이 나와 있지 않은 채이기에 알 수 없음
- Github 공개 되어 있지 않아서 신빙성 많이 떨어지는 논문
- 쓸데 없는 ablation으로 paper 채우는 듯한 노력이 보임 (대체 learning rate에 대한 ablation처럼 보이는 실험이 왜 진행되었는지 알 수 없음)
Reference
[1] Song, Xingchen, et al. "Speech-XLNet: Unsupervised Acoustic Model Pretraining for Self-Attention Networks." Proc. Interspeech 2020 (2020): 3765-3769.
[2] Yang, Zhilin, et al. "XLNet: Generalized Autoregressive Pretraining for Language Understanding." Advances in Neural Information Processing Systems 32 (2019): 5753-5763.
'Paper Review > Unsupervised, Self & Semi-supervised' 카테고리의 다른 글
| Audio ALBERT: A lite BERT for self-supervised learning of audio representation 리뷰 (0) | 2021.04.25 |
|---|---|
| Mockingjay: Unsupervised speech representation learning with deep bidirectional transformer encoders 리뷰 (0) | 2021.04.25 |
| DeCoAR: Deep Contextualized Acoustic Representations For Semi-Supervised Speech Recognition 리뷰 (0) | 2021.04.25 |
| wav2vec 2.0 리뷰 (0) | 2021.04.12 |
| vq-wav2vec 리뷰 (2) | 2021.04.11 |