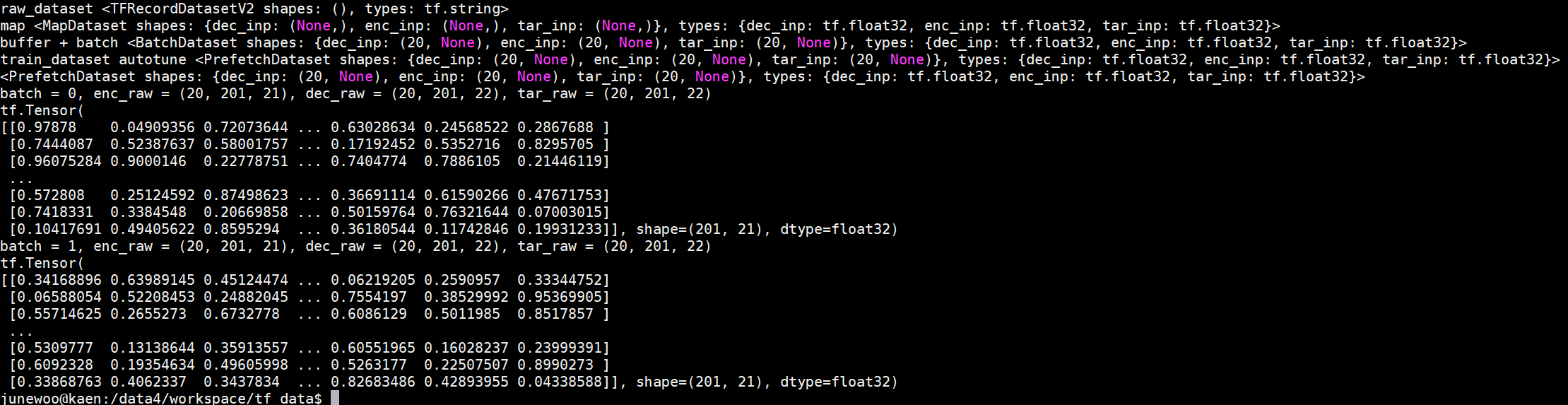
Tensorflow는 pytorch의 dataloader처럼 queue를 사용하여, 전체 데이터셋을 가져온 뒤 그것을 batch 만큼 쪼개서 하는 것이 살짝 번거롭다.
즉 이말을 다시 풀어보면, pytorch에서는 dataloader를 사용하여 여러 queue를 사용해서 batch 만큼 데이터셋을 가져온 뒤, 이것을 tensor로 바꿔서 model에 넣는 것이 수월한데 비해
Tensorflow에서는 tf.data.Dataset.from_tensor_slices 를 사용해서 전체 데이터셋을 가져오는 예제가 많다.
게다가 대용량 데이터셋을 사용하게 될 경우, 데이터셋의 총 사이즈가 3GB 정도가 넘어가면 tensorflow 는 API 관련 오류가 생기면서 data load가 안 될 때가 있다.
근 3일 정도 고생하면서 찾아본 정보들을 합쳐서, 음성 데이터셋의 stft 한 결과인 2차원 데이터셋을 tfrecord로 저장하는 방법을 소개한다.
# 전처리
음성(.wav)파일 모두에 대해, 2차원 stft를 얻었다고 가정하고 진행하겠다.
stft를 바꾸는 방법은 이 블로그 내에 있다.
import tensorflow as tf
print(tf.__version__)
import os
import librosa
from glob import glob
import numpy as np
list_inp = sorted(glob('/your/input/dataset/*/*.npz'))
list_tar = sorted(glob('/your/target/dataset/*/*.npz'))
print(len(list_inp))
위의 코드는 모든 음성 파일을 .npz 라는 numpy 형태의 data format으로 미리 저장해둔 상태이고, 이것을 glob으로 가져오는 모습이다. Seq2Seq 모델의 Encoder input인 list_inp와 Decoder input, Real value input인 list_tar의 전체를 가져온다.
2d numpy 값을 그대로 value=feature1 를 해주면, 오류가 생긴다. 이를 찾아보게 되면, tensorflow에서의 FloatList는 1차원 값만 넣어줄 수 있기 때문이다. 그러므로, flatten()을 하여 넣어준다.
나 같은 경우 input과 target을 모두 maximum legnth를 구하고 zeropadding하여 shape을 아는 상태이지만, 만약 데이터셋이 모두 다를 경우 feature['shape'] = tf.train.Feature(int_list=tf.train.IntList(value=feature1.shape) 을 대입하여 나중에 데이터셋을 실제로 model에 넣을 때 shape을 기억하여 변환할 수 있다.
그다음 features = tf.train.Features(feature=feature)를 통해 tensorflow의 tensor로 변환해주고,
example 또한 마찬가지로 변환해준다.
serialized = example.SerializeToString() 을 통하여 binary? 로 변환해준다. 마지막으로 tf.records 파일을 write 해주는 writer.write(serialized)를 해주면 끝난다.
이것을 batch size만큼 해준다...
전체코드는 아래와 같다.
# 전체 코드
import tensorflow as tf
print(tf.__version__)
import os
import librosa
from glob import glob
import numpy as np
def serialize_example(batch, list1, list2):
filename = "./train_set.tfrecords"
writer = tf.io.TFRecordWriter(filename)
for i in range(batch):
feature = {}
feature1 = np.load(list1[i])
feature2 = np.load(list2[i])
print('feature1 shape {} feature2 shape {}'.format(feature1.shape, feature2.shape))
feature['input'] = tf.train.Feature(float_list=tf.train.FloatList(value=feature1.flatten()))
feature['target'] = tf.train.Feature(float_list=tf.train.FloatList(value=feature2.flatten()))
features = tf.train.Features(feature=feature)
example = tf.train.Example(features=features)
serialized = example.SerializeToString()
writer.write(serialized)
print("{}th input {} target {} finished".format(i, list1[i], list2[i]))
list_inp = sorted(glob('/your/input/dataset/*/*.npz'))
list_tar = sorted(glob('/your/target/dataset/*/*.npz'))
print(len(list_inp))
serialize_example(len(list_inp), list_inp, list_tar)
input, target 각각 8백만개 씩 있는데, 이것들이 과연 tfrecords를 통해 저장하였을 때의 공간적 이득과, 시간이 얼마나 걸리는지 체크해봐야겠다.
체크 해본 뒤, Tfrecord 파일을 다시 원래대로 음성 데이터 spectrogram으로 복구하는 것을 이번주내로 올릴 예정이다.
Duplicate plugins for name projector 라는 에러가 생기면서 안된다.
3. 완전 삭제가 안됨
tensorflow-gpu, tensorboard 를 지우고, 재설치하여도 안될때가 있다.
** 해결법
아래의 코드를 그대로 복사하여 하나의 .py 로 만들고, 실행하면 다음과 같은 step을 알려준다.
# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""Self-diagnosis script for TensorBoard.
Instructions: Save this script to your local machine, then execute it in
the same environment (virtualenv, Conda, etc.) from which you normally
run TensorBoard. Read the output and follow the directions.
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
# This script may only depend on the Python standard library. It is not
# built with Bazel and should not assume any third-party dependencies.
import collections
import errno
import functools
import hashlib
import inspect
import logging
import os
import pipes
import shlex
import socket
import subprocess
import sys
import tempfile
import textwrap
import traceback
# A *check* is a function (of no arguments) that performs a diagnostic,
# writes log messages, and optionally yields suggestions. Each check
# runs in isolation; exceptions will be caught and reported.
CHECKS = []
# A suggestion to the end user.
# headline (str): A short description, like "Turn it off and on
# again". Should be imperative with no trailing punctuation. May
# contain inline Markdown.
# description (str): A full enumeration of the steps that the user
# should take to accept the suggestion. Within this string, prose
# should be formatted with `reflow`. May contain Markdown.
Suggestion = collections.namedtuple("Suggestion", ("headline", "description"))
def check(fn):
"""Decorator to register a function as a check.
Checks are run in the order in which they are registered.
Args:
fn: A function that takes no arguments and either returns `None` or
returns a generator of `Suggestion`s. (The ability to return
`None` is to work around the awkwardness of defining empty
generator functions in Python.)
Returns:
A wrapped version of `fn` that returns a generator of `Suggestion`s.
"""
@functools.wraps(fn)
def wrapper():
result = fn()
return iter(()) if result is None else result
CHECKS.append(wrapper)
return wrapper
def reflow(paragraph):
return textwrap.fill(textwrap.dedent(paragraph).strip())
def pip(args):
"""Invoke command-line Pip with the specified args.
Returns:
A bytestring containing the output of Pip.
"""
# Suppress the Python 2.7 deprecation warning.
PYTHONWARNINGS_KEY = "PYTHONWARNINGS"
old_pythonwarnings = os.environ.get(PYTHONWARNINGS_KEY)
new_pythonwarnings = "%s%s" % (
"ignore:DEPRECATION",
",%s" % old_pythonwarnings if old_pythonwarnings else "",
)
command = [sys.executable, "-m", "pip", "--disable-pip-version-check"]
command.extend(args)
try:
os.environ[PYTHONWARNINGS_KEY] = new_pythonwarnings
return subprocess.check_output(command)
finally:
if old_pythonwarnings is None:
del os.environ[PYTHONWARNINGS_KEY]
else:
os.environ[PYTHONWARNINGS_KEY] = old_pythonwarnings
def which(name):
"""Return the path to a binary, or `None` if it's not on the path.
Returns:
A bytestring.
"""
binary = "where" if os.name == "nt" else "which"
try:
return subprocess.check_output([binary, name])
except subprocess.CalledProcessError:
return None
def sgetattr(attr, default):
"""Get an attribute off the `socket` module, or use a default."""
sentinel = object()
result = getattr(socket, attr, sentinel)
if result is sentinel:
print("socket.%s does not exist" % attr)
return default
else:
print("socket.%s = %r" % (attr, result))
return result
@check
def autoidentify():
"""Print the Git hash of this version of `diagnose_tensorboard.py`.
Given this hash, use `git cat-file blob HASH` to recover the relevant
version of the script.
"""
module = sys.modules[__name__]
try:
source = inspect.getsource(module).encode("utf-8")
except TypeError:
logging.info("diagnose_tensorboard.py source unavailable")
else:
# Git inserts a length-prefix before hashing; cf. `git-hash-object`.
blob = b"blob %d\0%s" % (len(source), source)
hash = hashlib.sha1(blob).hexdigest()
logging.info("diagnose_tensorboard.py version %s", hash)
@check
def general():
logging.info("sys.version_info: %s", sys.version_info)
logging.info("os.name: %s", os.name)
na = type("N/A", (object,), {"__repr__": lambda self: "N/A"})
logging.info("os.uname(): %r", getattr(os, "uname", na)(),)
logging.info(
"sys.getwindowsversion(): %r",
getattr(sys, "getwindowsversion", na)(),
)
@check
def package_management():
conda_meta = os.path.join(sys.prefix, "conda-meta")
logging.info("has conda-meta: %s", os.path.exists(conda_meta))
logging.info("$VIRTUAL_ENV: %r", os.environ.get("VIRTUAL_ENV"))
@check
def installed_packages():
freeze = pip(["freeze", "--all"]).decode("utf-8").splitlines()
packages = {line.split(u"==")[0]: line for line in freeze}
packages_set = frozenset(packages)
# For each of the following families, expect exactly one package to be
# installed.
expect_unique = [
frozenset([
u"tensorboard",
u"tb-nightly",
u"tensorflow-tensorboard",
]),
frozenset([
u"tensorflow",
u"tensorflow-gpu",
u"tf-nightly",
u"tf-nightly-2.0-preview",
u"tf-nightly-gpu",
u"tf-nightly-gpu-2.0-preview",
]),
frozenset([
u"tensorflow-estimator",
u"tensorflow-estimator-2.0-preview",
u"tf-estimator-nightly",
]),
]
found_conflict = False
for family in expect_unique:
actual = family & packages_set
for package in actual:
logging.info("installed: %s", packages[package])
if len(actual) == 0:
logging.warning("no installation among: %s", sorted(family))
elif len(actual) > 1:
logging.warning("conflicting installations: %s", sorted(actual))
found_conflict = True
if found_conflict:
preamble = reflow(
"""
Conflicting package installations found. Depending on the order
of installations and uninstallations, behavior may be undefined.
Please uninstall ALL versions of TensorFlow and TensorBoard,
then reinstall ONLY the desired version of TensorFlow, which
will transitively pull in the proper version of TensorBoard. (If
you use TensorBoard without TensorFlow, just reinstall the
appropriate version of TensorBoard directly.)
"""
)
packages_to_uninstall = sorted(
frozenset().union(*expect_unique) & packages_set
)
commands = [
"pip uninstall %s" % " ".join(packages_to_uninstall),
"pip install tensorflow # or `tensorflow-gpu`, or `tf-nightly`, ...",
]
message = "%s\n\nNamely:\n\n%s" % (
preamble,
"\n".join("\t%s" % c for c in commands),
)
yield Suggestion("Fix conflicting installations", message)
@check
def tensorboard_python_version():
from tensorboard import version
logging.info("tensorboard.version.VERSION: %r", version.VERSION)
@check
def tensorflow_python_version():
import tensorflow as tf
logging.info("tensorflow.__version__: %r", tf.__version__)
logging.info("tensorflow.__git_version__: %r", tf.__git_version__)
@check
def tensorboard_binary_path():
logging.info("which tensorboard: %r", which("tensorboard"))
@check
def addrinfos():
sgetattr("has_ipv6", None)
family = sgetattr("AF_UNSPEC", 0)
socktype = sgetattr("SOCK_STREAM", 0)
protocol = 0
flags_loopback = sgetattr("AI_ADDRCONFIG", 0)
flags_wildcard = sgetattr("AI_PASSIVE", 0)
hints_loopback = (family, socktype, protocol, flags_loopback)
infos_loopback = socket.getaddrinfo(None, 0, *hints_loopback)
print("Loopback flags: %r" % (flags_loopback,))
print("Loopback infos: %r" % (infos_loopback,))
hints_wildcard = (family, socktype, protocol, flags_wildcard)
infos_wildcard = socket.getaddrinfo(None, 0, *hints_wildcard)
print("Wildcard flags: %r" % (flags_wildcard,))
print("Wildcard infos: %r" % (infos_wildcard,))
@check
def readable_fqdn():
# May raise `UnicodeDecodeError` for non-ASCII hostnames:
# https://github.com/tensorflow/tensorboard/issues/682
try:
logging.info("socket.getfqdn(): %r", socket.getfqdn())
except UnicodeDecodeError as e:
try:
binary_hostname = subprocess.check_output(["hostname"]).strip()
except subprocess.CalledProcessError:
binary_hostname = b"<unavailable>"
is_non_ascii = not all(
0x20 <= (ord(c) if not isinstance(c, int) else c) <= 0x7E # Python 2
for c in binary_hostname
)
if is_non_ascii:
message = reflow(
"""
Your computer's hostname, %r, contains bytes outside of the
printable ASCII range. Some versions of Python have trouble
working with such names (https://bugs.python.org/issue26227).
Consider changing to a hostname that only contains printable
ASCII bytes.
""" % (binary_hostname,)
)
yield Suggestion("Use an ASCII hostname", message)
else:
message = reflow(
"""
Python can't read your computer's hostname, %r. This can occur
if the hostname contains non-ASCII bytes
(https://bugs.python.org/issue26227). Consider changing your
hostname, rebooting your machine, and rerunning this diagnosis
script to see if the problem is resolved.
""" % (binary_hostname,)
)
yield Suggestion("Use a simpler hostname", message)
raise e
@check
def stat_tensorboardinfo():
# We don't use `manager._get_info_dir`, because (a) that requires
# TensorBoard, and (b) that creates the directory if it doesn't exist.
path = os.path.join(tempfile.gettempdir(), ".tensorboard-info")
logging.info("directory: %s", path)
try:
stat_result = os.stat(path)
except OSError as e:
if e.errno == errno.ENOENT:
# No problem; this is just fine.
logging.info(".tensorboard-info directory does not exist")
return
else:
raise
logging.info("os.stat(...): %r", stat_result)
logging.info("mode: 0o%o", stat_result.st_mode)
if stat_result.st_mode & 0o777 != 0o777:
preamble = reflow(
"""
The ".tensorboard-info" directory was created by an old version
of TensorBoard, and its permissions are not set correctly; see
issue #2010. Change that directory to be world-accessible (may
require superuser privilege):
"""
)
# This error should only appear on Unices, so it's okay to use
# Unix-specific utilities and shell syntax.
quote = getattr(shlex, "quote", None) or pipes.quote # Python <3.3
command = "chmod 777 %s" % quote(path)
message = "%s\n\n\t%s" % (preamble, command)
yield Suggestion("Fix permissions on \"%s\"" % path, message)
@check
def source_trees_without_genfiles():
roots = list(sys.path)
if "" not in roots:
# Catch problems that would occur in a Python interactive shell
# (where `""` is prepended to `sys.path`) but not when
# `diagnose_tensorboard.py` is run as a standalone script.
roots.insert(0, "")
def has_tensorboard(root):
return os.path.isfile(os.path.join(root, "tensorboard", "__init__.py"))
def has_genfiles(root):
sample_genfile = os.path.join("compat", "proto", "summary_pb2.py")
return os.path.isfile(os.path.join(root, "tensorboard", sample_genfile))
def is_bad(root):
return has_tensorboard(root) and not has_genfiles(root)
tensorboard_roots = [root for root in roots if has_tensorboard(root)]
bad_roots = [root for root in roots if is_bad(root)]
logging.info(
"tensorboard_roots (%d): %r; bad_roots (%d): %r",
len(tensorboard_roots),
tensorboard_roots,
len(bad_roots),
bad_roots,
)
if bad_roots:
if bad_roots == [""]:
message = reflow(
"""
Your current directory contains a `tensorboard` Python package
that does not include generated files. This can happen if your
current directory includes the TensorBoard source tree (e.g.,
you are in the TensorBoard Git repository). Consider changing
to a different directory.
"""
)
else:
preamble = reflow(
"""
Your Python path contains a `tensorboard` package that does
not include generated files. This can happen if your current
directory includes the TensorBoard source tree (e.g., you are
in the TensorBoard Git repository). The following directories
from your Python path may be problematic:
"""
)
roots = []
realpaths_seen = set()
for root in bad_roots:
label = repr(root) if root else "current directory"
realpath = os.path.realpath(root)
if realpath in realpaths_seen:
# virtualenvs on Ubuntu install to both `lib` and `local/lib`;
# explicitly call out such duplicates to avoid confusion.
label += " (duplicate underlying directory)"
realpaths_seen.add(realpath)
roots.append(label)
message = "%s\n\n%s" % (preamble, "\n".join(" - %s" % s for s in roots))
yield Suggestion("Avoid `tensorboard` packages without genfiles", message)
# Prefer to include this check last, as its output is long.
@check
def full_pip_freeze():
logging.info("pip freeze --all:\n%s", pip(["freeze", "--all"]).decode("utf-8"))
def set_up_logging():
# Manually install handlers to prevent TensorFlow from stomping the
# default configuration if it's imported:
# https://github.com/tensorflow/tensorflow/issues/28147
logger = logging.getLogger()
logger.setLevel(logging.INFO)
handler = logging.StreamHandler(sys.stdout)
handler.setFormatter(logging.Formatter("%(levelname)s: %(message)s"))
logger.addHandler(handler)
def main():
set_up_logging()
print("### Diagnostics")
print()
print("<details>")
print("<summary>Diagnostics output</summary>")
print()
markdown_code_fence = "``````" # seems likely to be sufficient
print(markdown_code_fence)
suggestions = []
for (i, check) in enumerate(CHECKS):
if i > 0:
print()
print("--- check: %s" % check.__name__)
try:
suggestions.extend(check())
except Exception:
traceback.print_exc(file=sys.stdout)
pass
print(markdown_code_fence)
print()
print("</details>")
for suggestion in suggestions:
print()
print("### Suggestion: %s" % suggestion.headline)
print()
print(suggestion.description)
print()
print("### Next steps")
print()
if suggestions:
print(reflow(
"""
Please try each suggestion enumerated above to determine whether
it solves your problem. If none of these suggestions works,
please copy ALL of the above output, including the lines
containing only backticks, into your GitHub issue or comment. Be
sure to redact any sensitive information.
"""
))
else:
print(reflow(
"""
No action items identified. Please copy ALL of the above output,
including the lines containing only backticks, into your GitHub
issue or comment. Be sure to redact any sensitive information.
"""
))
if __name__ == "__main__":
main()
최근에 사용했던 간단한 라이브러리 Transformer 모델의 Self-Attention이다.
이 Function을 사용하기 위해서는 따로 import를 해줘야하는데 아래와 같이 하면 된다.
from keras_self_attention import SeqSelfAttention
자 이제 CNN 몇개와 RNN 몇개를 쌓고, 그 아래에 Self-Attention을 쌓았다고 가정해보자.
이 모델을 Fine-tune 하기 위해 일정 learning rate로 돌려놓고, 어느정도 loss를 깎은 다음 일정 이상 loss가 떨어지지 않으면 early stopping을 하여 learning rate를 기존보다 0.1배 정도로 낮춰서 fine-tune 할 예정이다. 이를 위해 모델을 save해야한다.
그럼 모델을 load할 때 종속성 문제가 생길 수 있다. 위의 SeqSelfAttention 인식을 못 할 수 있는 것이다.
내가 안되었던 경우는 다음과 같다.
from keras.models import load_model, Model import tensorflow as tf import os import time from keras_self_attention import SeqSelfAttention global graph, model graph = tf.get_default_graph() ### GPU Setting : Not Using GPU os.environ["CUDA_VISIBLE_DEVICES"]="-1" # Load Model model = load_model('/data/Auditory_Emotion_Recognition/model_attention/fianl_emotion_model.h5')
코드를 보면 단지 model을 load하는데, Unknown layer라고 뜬다. 아래의 사진은 그 현상을 얘기한다.
즉 SeqSelfAttention을 import 하였는데도 이러한 문제가 생긴다.
이를 해결 하기 위해 model load시 다음과 같은 줄을 선언해주면 쉽게 해결할 수 있다.
model = load_model('/data/Auditory_Emotion_Recognition/model_attention/fianl_emotion_model.h5',custom_objects={'SeqSelfAttention':SeqSelfAttention})
들어가보면 맨 윗창에 Model Visualization이라고 나와 있다. 뜻 그대로 모델을 시각화 하겠다라는 뜻일듯.
예제에 나와 있는 것 처럼 그림으로 보고 싶은 모델을 불러온 뒤 예제처럼 코딩을 하면 저장이 된다.
나의 코드는 다음과 같다.
from keras.utils import plot_model
from keras.models import load_model from keras_self_attention import SeqSelfAttention
model = load_model('/data/Auditory_Emotion_Recognition/model_attention/4emotions_auditory_cnn_model_self_GAP_pati50_epoch200_dropout0.2,relu_lr1e-05_8conv5dim+1GRU2FC_Zscore_lrdecay5.4e-08_acc:0.5498_test:_57.42.h5',custom_objects={'SeqSelfAttention':SeqSelfAttention}) plot_model(model, to_file='./model.png')
from keras.utils import plot_model: keras에서 모델을 그리기 위해 필요한 라이브러리 import
from keras.models import load_model: 저장된 모델을 불러오기 위한 라이브러리 import
from ~ SeqSelfAttention: SelfAttention을 보기 위한 라이브러리 import
model ~ -> 불러올 모델의 위치를 load_model을 통해 불러온 뒤 model로 선언
plot_model(model, to_file='./model.png'): model 을 그림으로 그리는 건데, 이 때 ./ 는 코드상의 디렉토리에 model.png 로 저장하겠다는 뜻이다.