이번에 리뷰할 논문은 Almost Unsupervised Text to Speech and Automatic Speech Recognition [1]이며, ICLR 2019에 억셉되었다.
Overview
- 음성 및 텍스트 영역 모두에서 언어 이해 및 모델링 기능을 구축하기 위해 짝을 이루지 않는 음성 및 텍스트 데이터에 대한 self-supervised learning 아이디어를 활용함
- 특히, 인코더-디코더 프레임 워크에서 손상된 음성 및 텍스트를 재구성하기 위해 Denoising Auto-Encoder를 사용함
- 역 번역의 개념인 Dual transformation을 사용하여 텍스트를 음성으로 (TTS) 및 음성을 텍스트로 (ASR) 변환하는 기능을 제안함
- 음성 및 텍스트 시퀀스가 일반적으로 Neural Machine Translation과 같은 다른 시퀀스-투-시퀀스 학습 작업보다 길다는 점을 고려하면 오류 전파로 인해 더 많은 어려움을 겪을텐데, 이는 생성된 시퀀스의 오른쪽 부분이 일반적으로 왼쪽 부분보다 나쁘다는 문제를 나타냄
- 특히 Supervised 데이터가 부족하여 리소스가 없거나 리소스가 부족한 설정에서(즉 데이터가 부족한 상황) 자주 나타나는 현상임
- 따라서 Denoising Auto-Encoder 및 Dual Transformation을 기반으로 텍스트와 음성 모두에 대해 양방향 시퀀스 모델링을 추가로 활용하여 오류 전파 문제를 완화하는 것을 제안함
Intro & Related works
- 최근, 최첨단 성능의 TTS 및 ASR 시스템은 대부분 Neural Networks 기반이며, 모두 대규모 데이터를 많이 사용하므로, 쌍을 이루는 음성 및 텍스트 데이터셋이 부족한 언어에는 문제가 발생함
- 비지도 ASR에 초첨을 맞춘 작업에서는 TTS의 추가 정보를 활용하지 않는데(2019년 기준), 이는 ASR의 이중 작업이며, ASR의 성능을 향상시킬 수 있는 큰 잠재력임
- 게다가 비지도 ASR은 일반적으로 음성 파형을 단어 또는 음소로 먼저 분할하고, 세그먼트 수준에서 텍스트 데이터와 음성을 정렬하는 일부 작업별 알고리즘을 활용함
- 그러나 TTS는 일반적으로 음성 파형을 Mel-spectrogram 또는 MFCC로 변환하여 프레임 수준에서 처리함
- 따라서 비지도 ASR 용으로 설계된 알고리즘을 TTS에 쉽게 적용하기 힘듬
- 샘플이 거의 없는 특정 화자의 음성을 합성하려는 작업은 일반적으로 전이 학습 문제로 간주되지만, 비지도 학습 문제가 아닌 다른 화자의 레이블이 지정된 다량의 음성 및 텍스트 데이터를 활용함
- 그리하여 이 논문에서는, TTS와 ASR 작업의 이중 특성으로부터 영감을 받아 TTS와 ASR 모두에 대해 몇 가지 쌍을 이루는 음성 및 텍스트 데이터와 추가로 쌍을 이루지 않는 데이터를 활용하여 거의 감독되지 않는 새로운 방법을 제안함
Method
1. DAE (Denoising Auto-Encoder)
- 짝을 이루지 않는 대량의 음성 및 텍스트 데이터를 감안할 때 표현 추출 및 언어 모델링 기능을 구축하는 것이 음성과 텍스트 간의 변환을 위한 첫 번째 단계임
- 이를 위해 논문에서는 DAE를 활용하여 손상된 버전 자체에서 음성 및 텍스트 시퀀스를 재구성함
- 노이즈 제거 자동 인코더는 일반적인자가지도 학습 방법이며 비지도 학습에 널리 사용되는데, 음성 및 텍스트 데이터에 대한 노이즈 제거 자동 인코더의 손실 함수 $L^{dae}$ 는 다음과 같이 공식화됨
$L^{dae}=L_s(x|C(x);\theta_{enc}^S,\theta_{dec}^S)+L_T(y|C(y);\theta_{enc}^T,\theta_{dec}^T)$
- 여기에서, $S, T$는 각각 음성과 텍스트 도메인의 시퀀스 데이터이며, $\theta_{enc}^T,\theta_{dec}^T$는 음성 인코더, 음성 디코더, 텍스트 인코더 그리고 텍스트 디코더의 파라미터들임
- $C$는 0값을 갖는 벡터로 일부 요소를 무작위로 마스킹하거나 음성 및 텍스트 시퀀스의 특정 창에서 요소를 교체하는 손상된 연산을 나타냄
- $L_s, L_T$ 각각 음성 및 텍스트 대상 시퀀스의 손실을 나타냄
- 이를 정리하면, $L_s$ 는 음성의 Mean Squared Errors로, $L_T$는 text Classification으로 나타낼 수 있음
2. Dual Transformation (DT)
1) DT는 TTS 및 ASR 작업의 이중 특성을 활용하고 텍스트를 음성으로 (TTS) 및 음성을 텍스트로 (ASR) 변환하는 기능을 개발하는 핵심 구성 요소임
- ASR 모델을 사용하여 음성 시퀀스 $x$를 텍스트 시퀀스 $\hat{y}$로 변환 한 다음 변환 된 쌍 $(\hat{y},x)$에서 TTS 모델을 훈련시킴
- 마찬가지로 TTS 모델에 의해 생성 된 변환 된 쌍 $(\hat{x},y)$에 대해 ASR 모델을 훈련함
- 이중 변환은 번역을 위해 단일 언어 데이터를 활용하는 가장 효과적인 방법 중 하나인 backtranslation(역번역) 으로서, Neural Machine Translation
- DT는 번역을 위해 단일 언어 데이터를 활용하는 가장 효과적인 방법 중 하나인 Neural Machine Translation의 backtranslation(역-번역) 방법에서 제안되었음
2) 손실 함수 $L^{dt}$ 다음 두 부분으로 구성됨
$L^{dt}=L_S(x|\hat{y};\theta_{enc}^T,\theta_{dec}^S)+L_T(y|\hat{x};\theta_{enc}^S,\theta_{dec}^T)$
- 여기에서, $\hat{y}$=argmax$P(y|x;\theta_{enc}^s,\theta_{dec}^S)$ 및, $\hat{x}=f(y;\theta_{enc}^T,\theta_{dec}^S)$는 각각 음성 $x$ 및 텍스트 $y$에서 변환된 텍스트 및 음성 시퀀스임
- 모델 학습 중에는 TTS 모델이 변환된 최신 텍스트 시퀀스를 활용하는 DT가 즉시 실행되며, 훈련을 위해 ASR 모델에 의해 또는 그 반대로 TTS 및 ASR의 정확도가 점진적으로 향상될 수 있도록 보장함
3. Bidirectional Sequence Modeling
1) Seq2seq 학습은 일반적으로 오류 전파로 어려움을 겪음
- 예를 들어, 추론 중에 요소가 실수로 예측되면 오류가 전파되며, 이로 인해 생성된 시퀀스의 오른쪽 부분 (끝 부분)이 왼쪽 부분보다(앞 부분) 정확도가 떨어짐
- 음성 및 텍스트 시퀀스는 일반적으로 신경 기계 번역과 같은 다른 NLP 작업의 시퀀스보다 길며 오류 전파로 인해 더 많은 문제를 겪을 수 있음
- 예를 들어, 실험에서 DT중에 생성된 음성 시퀀스의 오른쪽 부분은 일반적으로 반복되는 단어나 누락된 단어가 있는 왼쪽 부분보다 품질이 낮음
- 결과적으로 훈련을 위해 변환된 데이터에 의존하는 DT이 영향을 받고 텍스트의 오른쪽 부분과 음성 시퀀스가 잘 훈련될 수 없음
- 따라서 TTS 및 ASR 모델은 모두 시퀀스의 오른쪽 부분, 특히 label이 있는 데이터가 부족하여 리소스가 낮거나 없는 환경에서 낮은 품질의 결과가 도출되는 경향이 있음
2) 위의 문제를 해결하기 위해 양방향 시퀀스 모델링을 활용하여 왼쪽에서 오른쪽 및 오른쪽에서 왼쪽 방향으로 음성 및 텍스트 시퀀스를 생성하는 것을 제안함
- 이러한 방식으로 기존의 DT 프로세스에서 항상 품질이 낮았던 시퀀스의 오른쪽 부분을 좋은 품질을 유지한 채로 오른쪽에서 왼쪽 방향으로 생성 가능함
- 결과적으로, 훈련을 위해 변환된 데이터에 의존하는 이중 작업은 시퀀스의 오른쪽 부분에서 개선된 품질의 혜택을 받을 것이며, 시퀀스의 왼쪽과 오른쪽 부분 사이의 생성 품질에서 더 균형을 이룰 것임
- 원래 왼쪽에서 오른쪽으로 생성된 것보다 더 높은 변환 정확도를 제공함
- 동시에 양방향 시퀀스 모델링은 양방향으로 데이터를 활용하는 데이터 증대 효과로도 작용할 수 있으며, 이는 특히 거의 비지도 학습 설정에서 쌍을 이룬 데이터가 거의 없을 때 유용하게 사용될 수 있음
- 양방향 DAE는 다음과 같이 구성할 수 있음

- 왼쪽에서 오른쪽 및 오른쪽에서 왼쪽 방향으로 손상된 음성 및 텍스트 시퀀스를 재구성하는 경우 $C(\cdot)$은 masking 연산임
- 시퀀스를 두 방향으로 모델링할 때 모델 매개 변수를 공유함
- DAE 및 DT를 기반으로 한 양방향 시퀀스 모델링은 왼쪽에서 오른쪽 및 오른쪽에서 왼쪽 세대 간에 모델을 공유함
- 즉, 시퀀스를 양방향으로 생성하는 하나의 모델을 학습할 수 있으며, 모델 매개 변수를 줄이는 것도 가능함
- 모델에게 훈련과 추론의 시작 요소로 제로 벡터를 사용하는 기존의 디코더와는 달리, 제안하는 방법은 두 개의 학습 가능한 내장 벡터를 훈련과 추론 방향을 나타내는 두 개의 시작 요소로, 하나는 왼쪽에서 오른쪽으로, 다른 하나는 오른쪽에서 왼쪽으로 사용함
- 따라서 총 4 개의 시작 임베딩을 학습함
- 2 개는 음성 생성 용이고 다른 2 개는 텍스트 생성 용임
- TTS 및 ASR의 음성 및 텍스트 시퀀스는 일반적으로 monotonic attention에 의해 alignment되므로, 예를 들어 디코더의 음성 시퀀스의 왼쪽 부분은 일반적으로 TTS의 인코더에서 텍스트 시퀀스의 왼쪽 부분에 집중될 수 있음
- 왼쪽에서 오른쪽 생성과 일치하기 위해 오른쪽에서 왼쪽 방향으로 대상 시퀀스를 생성할 때 오른쪽에서 왼쪽 방향으로 소스 시퀀스를 인코더에 공급함
- 따라서 소스 시퀀스를 역순으로 대상 시퀀스와 일치시킴
4. Proposed model details

1) 시퀀스 모델링에서 기존 RNN / CNN 보다 장점이 있기 때문에 Transformer로 선택하였음
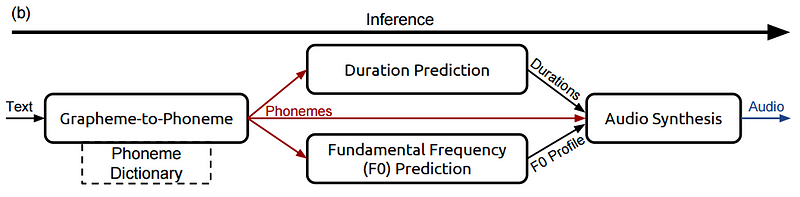
2) 그림 a
- 녹색 및 노란색 화살표는 음성 및 텍스트에 대한 DAE를 나타냄
- 빨간색 화살표는 텍스트에서 음성으로 (TTS)
- 파란색 화살표는 음성에서 텍스트로 (ASR)의 DT를 나타냄
- DAE와 DT 모두 양방향 시퀀스 모델링을 포함함
3) 그림 b
- Transformer를 기반으로 하는 음성 및 텍스트 인코더 및 디코더
- Transformer는 주로 교차 위치 정보를 추출하기 위한 MHA와 각 위치에서 non-linear 변환을 보장하기 위한 FFN로 구성된 self-attention 메커니즘을 사용하고, 각각에 residual 연결 및 layer norm이 이루어짐
- 디코더는 인코더의 마지막 레이어에서 hidden representation을 추출하기 위해 추가 MHA를 사용함
- 인코더와 디코더는 모두 input d_model이 256이고 FFN은 1024의 크기이며, 4 layer로 쌓았음
- TTS와 ASR은 인코더와 디코더에 대해 동일한 모델 구조를 공유하지만 모델 매개 변수가 다름 (공개 안되어있음)
4) 그림 c
- 음성 및 텍스트에 대한 입력 및 출력 모듈이며, 음성 입력 모듈 (그림 c의 왼쪽 하단)은 hidden size가 256 인 Pre-Net으로 구성되며 출력 차원은 Transformer의 hidden size인 256과 같음
- 음성 출력 모듈 (그림 c의 왼쪽 상단)은 두 가지 구성 요소로 구성됨
- 하나는 출력 차원이 1 인 stop linear layer와 현재 디코딩 단계가 중지되어야 하는지 여부를 예측하는 sigmoid임
- 다른 하나는 각 단계에서 80 차원 벡터로 mel-spectrogram을 생성하기 위해 추가 Post-Net이 있는 mel linear layer임
- Post-Net은 생성된 mel-spectrogram의 품질을 개선하는 것을 목표로 하는 256의 hidden size를 갖는 5-layer 1-D Convolution 네트워크로 구성됨
- Griffin-Lim 알고리즘을 사용하여 mel-spectrogram을 audio로 변환함
- 텍스트 입력 모듈 (그림 c의 오른쪽 하단)은 phoneme 임베딩으로, phoneme ID를 임베딩으로 변환함
- 출력 모듈의 텍스트 linear layer (그림 c의 오른쪽 상단)와 phoneme 임베딩의 매개 변수를 공유함
- 텍스트 시퀀스는 모델에 입력하기 전에 먼저 텍스트-음소 변환기를 사용하여 음소 시퀀스로 변환됨
[1] Ren, Yi, et al. "Almost unsupervised text to speech and automatic speech recognition." International Conference on Machine Learning. PMLR, 2019.
'Paper Review > Speech Recognition' 카테고리의 다른 글
| Self-Training for End-to-End Speech Recognition 리뷰 (0) | 2021.07.04 |
|---|---|
| Sequence-to-sequence speech recognition with time-depth separable convolutions 리뷰 (0) | 2021.07.04 |
| SpecAugment 리뷰 (2) | 2021.01.10 |
| Feature Learning in Deep Neural Networks - A Study on Speech Recognition Tasks (0) | 2021.01.08 |
| Listen, Attend and Spell 리뷰 (0) | 2019.03.19 |