글이 많이 늦었습니다. 졸업 준비하느라 바빠져서...
이전 포스팅에 TfRecord로 모든 음성 데이터에 대해 byte로 읽고, 저장하는 것 까지 처리하였다.
이제 해야되는 것은? 모델 설계 한 이후 tensorflow 에서 제공하는 tf.Data를 사용하여 shuffle -> prefetch -> batch로 데이터를 나눈 뒤 모델에 넣는 것을 해주면 된다.
import tensorflow as tf
record_file = './tf_records_example.tfrecords' # previously saved tfrecords dataset
batch_size = 20
먼저 https://kaen2891.tistory.com/65 글을 참조해주셔서, record file이 저장되는것을 확인한 뒤, 이 파일을 불러오면 된다. 이 파일을 record_file='' << ' ' 사이에 directory에 넣는다.
그 후, 매 train step 마다 몇 개의 batch_size로 할 지에 대해 선언한다.
spectrum_feature_description = {
'enc_inp': tf.io.FixedLenSequenceFeature ([], tf.float32, allow_missing=True),
'dec_inp': tf.io.FixedLenSequenceFeature ([], tf.float32, allow_missing=True),
'tar_inp': tf.io.FixedLenSequenceFeature ([], tf.float32, allow_missing=True)
}
def _parse_spec_function(example_proto):
# Parse the input tf.Example proto using the dictionary above.
return tf.io.parse_single_example(example_proto, spectrum_feature_description)
def input_fn(record_file, batch_size, buffer_size):
dataset = tf.data.TFRecordDataset(record_file)
print('raw_dataset', dataset) # ==> raw_dataset <TFRecordDatasetV2 shapes: (), types: tf.string>
parsed_spec_dataset = dataset.map(_parse_spec_function)
print('map', parsed_spec_dataset)
#parsed_spec_dataset = parsed_spec_dataset.cache()
#print('cache', parsed_spec_dataset)
train_dataset = parsed_spec_dataset.shuffle(buffer_size).batch(batch_size, drop_remainder=True)
print('buffer + batch', train_dataset)
train_dataset = train_dataset.prefetch(tf.data.experimental.AUTOTUNE)
print('train_dataset autotune', train_dataset)
return train_dataset
train_dataset = input_fn(record_file, batch_size=batch_size, buffer_size=10)
print(train_dataset)
그 다음 할 일은, input_fn 의 함수에서 매 dataset을 불러오는 것을 만들어 줄 것이다.
input_fn에는 record_file과 batch_size, buffer_size 를 함수 인자로 받은 뒤 record_file을 읽는다.
여기까지 해주면 byte type의 data들을 읽은 것이고, 이전 글에서 나는 데이터를 3가지 형태로 받았다.
enc_inp, dec_inp, tar_inp 이렇게 3개로 받았다.
즉 이 3가지의 data 형태로 복원해주기 위해서는 _parse_spec_function이 필요하다.
여기에서 spectrum_feature_description dictionary 를 호출하여 이 dict 형태로 저장할 수 있다.
이렇게까지 받은 것이, parsed_spec_dataset 이다. 그 이후, 일반적인 tensorflow의 dataset 처리해주는 것처럼 해주면 된다.
위에서 처리된 parsed_spec_dataset에 shuffle을 buffer_size 넣어서 해주고, 이것을 batch_size 만큼 batch 형태로 해준다.
drop_remainder는 데이터 개수가 batch에 나뉘어지지 않을 경우, 마지막에는 빈 만큼 넣어주는 것으로 이해하면 된다.
마지막으로, prefetch를 사용하여 queue에 넣어준 뒤, dataset을 model에 넣어주면 된다.
for (batch, spec) in enumerate(train_dataset):
enc_raw = spec['enc_inp'].numpy()
enc_raw = tf.reshape(enc_raw, [batch_size, 201, 21]) # batch, d_model, seq_len
dec_raw = spec['dec_inp'].numpy()
dec_raw = tf.reshape(dec_raw, [batch_size, 201, 22])
tar_raw = spec['tar_inp'].numpy()
tar_raw = tf.reshape(tar_raw, [batch_size, 201, 22])
print('batch = {}, enc_raw = {}, dec_raw = {}, tar_raw = {}'.format(batch, enc_raw.shape, dec_raw.shape, tar_raw.shape))
print(enc_raw[0])
실제로 모델에 넣어서 돌리는 것이 아닌, 가상으로 위의 코드처럼 짜보았다. train_dataset은 현재 TfRecordfile을 batch_size 만큼 받아올 수 있다.
여기에서 끝인가? 아니다. batch, spec 에서 spec에는 위의 dictionary형태로 저장되어 있다. 이것을 긁어와야 한다. 어떻게? key를 사용하여
enc_raw = spec['enc_inp'].numpy() 를 사용하여 spec에서 enc_inp를 가져온다.
그럼 이대로 쓰면 되지 않냐고 할 수 있는데, 안된다.
왜냐하면 위의 dictionary를 사용하여 3개의 데이터를 받았고, 이를 numpy 형태로 바꾸었지만, 우리는 아직 이 데이터셋의 shape에 대해서는 모른다.
그래서 바로 아래의 enc_raw = tf.reshape(enc_raw, [batch_size, 201, 21]) 을 하여 shape을 살려줘야 한다.
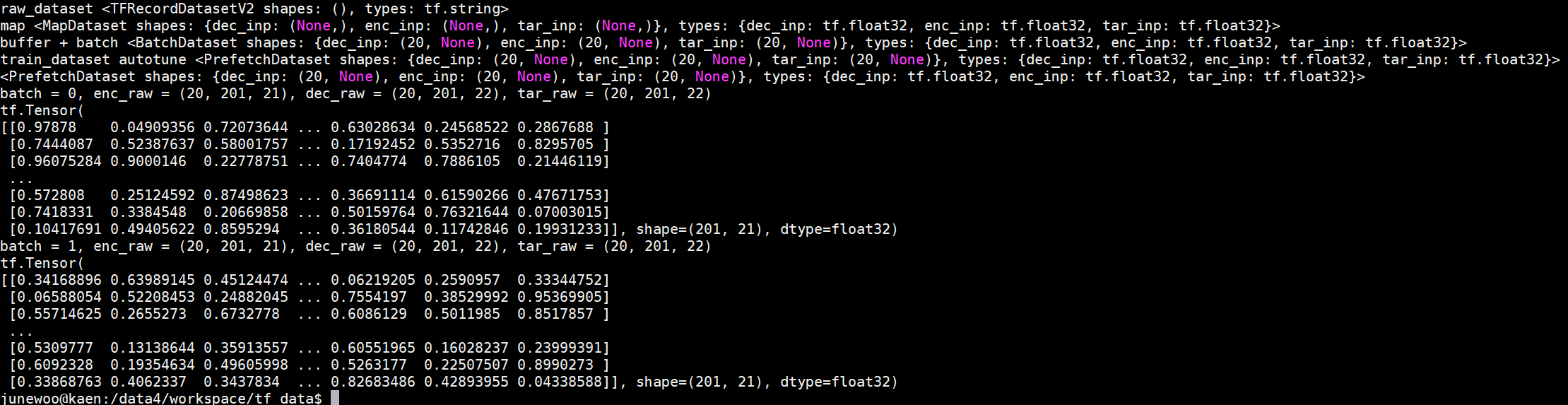
batch, enc_raw, dec_raw, tar_raw의 shape을 출력하면 아래와 같은 결과를 얻을 수 있다.

마지막으로 enc_raw[0]를 출력하면, (20, 201, 21)의 첫 번째 vector를 가져오는 것이므로 (201, 21)의 tensorflow Tensor를 볼 수 있다.

전체 코드는 아래와 같으며,
import tensorflow as tf
'''
This code is for read form tfrecords file and get batch for training in tensorflow 2.0
In tf_records_example.tfrecords files, dataset is consist of 2d array with 50 batch size. So the enc_inp shape is (50, 201, 21) and the dec_inp and tar_inp shape is (50, 201, 22)
You can use this code for tfrecords file to training
Authors: June-Woo Kim (kaen2891@gmail.com)
'''
spectrum_feature_description = {
'enc_inp': tf.io.FixedLenSequenceFeature ([], tf.float32, allow_missing=True),
'dec_inp': tf.io.FixedLenSequenceFeature ([], tf.float32, allow_missing=True),
'tar_inp': tf.io.FixedLenSequenceFeature ([], tf.float32, allow_missing=True)
}
def _parse_spec_function(example_proto):
# Parse the input tf.Example proto using the dictionary above.
return tf.io.parse_single_example(example_proto, spectrum_feature_description)
def input_fn(record_file, batch_size, buffer_size):
dataset = tf.data.TFRecordDataset(record_file)
print('raw_dataset', dataset) # ==> raw_dataset <TFRecordDatasetV2 shapes: (), types: tf.string>
parsed_spec_dataset = dataset.map(_parse_spec_function)
print('map', parsed_spec_dataset)
#parsed_spec_dataset = parsed_spec_dataset.cache()
#print('cache', parsed_spec_dataset)
train_dataset = parsed_spec_dataset.shuffle(buffer_size).batch(batch_size, drop_remainder=True)
print('buffer + batch', train_dataset)
train_dataset = train_dataset.prefetch(tf.data.experimental.AUTOTUNE)
print('train_dataset autotune', train_dataset)
return train_dataset
record_file = './tf_records_example.tfrecords'
batch_size = 20
train_dataset = input_fn(record_file, batch_size=batch_size, buffer_size=10)
print(train_dataset)
for (batch, spec) in enumerate(train_dataset):
enc_raw = spec['enc_inp'].numpy()
enc_raw = tf.reshape(enc_raw, [batch_size, 201, 21]) # batch, d_model, seq_len
dec_raw = spec['dec_inp'].numpy()
dec_raw = tf.reshape(dec_raw, [batch_size, 201, 22])
tar_raw = spec['tar_inp'].numpy()
tar_raw = tf.reshape(tar_raw, [batch_size, 201, 22])
print('batch = {}, enc_raw = {}, dec_raw = {}, tar_raw = {}'.format(batch, enc_raw.shape, dec_raw.shape, tar_raw.shape))
print(enc_raw[0])
출력 output은 아래와 같다.
제 코드는 https://github.com/kaen2891/utils 에서 깔끔하게 확인하실 수 있습니다.
'딥러닝 > TF2.0 & Keras' 카테고리의 다른 글
| Tensorflow 2.0 벡터 여러개, 여러 차원으로 복사 (tensorflow tf.repeat) (0) | 2020.08.10 |
|---|---|
| 2차원 음성 대용량 데이터셋을 TfRecord로 만들기 (0) | 2020.04.17 |
| tensorboard (2.0) 안될 때 해결법 (0) | 2019.12.02 |
| Keras 모델 load시 Unknown layer, 외부 라이브러리 해결 방법 (2) | 2019.03.19 |
| Keras 모델 그림으로 저장 (0) | 2019.03.19 |