728x90
잘 정제된 음성 데이터셋의 경우 (특히 딥러닝 음성인식 및 오디오 처리 학습용의 경우) 거의 Mono channel로 공개가 되어있다.
하지만 다양한 실환경에서 녹음된 오디오 데이터셋의 경우, 녹음 기기에 따라 2이상의 channel로 구성된, Stereo channel로 공개가 된 데이터들이 많다.
간단하게 아래와 같이 음성을 로드하게 되면
import torchaudio
import torch
waveform = './test.wav'
y, sr = torchaudio.load(waveform)
y의 size를 출력해보면, 예를 들어, (2, 100) 과 같이 나올 수가 있다.
이를 Stereo channel이라고 한다.
간단하게 아래의 그림을 보면 이해가 쉽게 될 것 같은데, stereo는 채널 별 들리는 소리가 약간 다른 반면, mono는 stereo의 평균을 낸 것으로 간주할 수 있다.
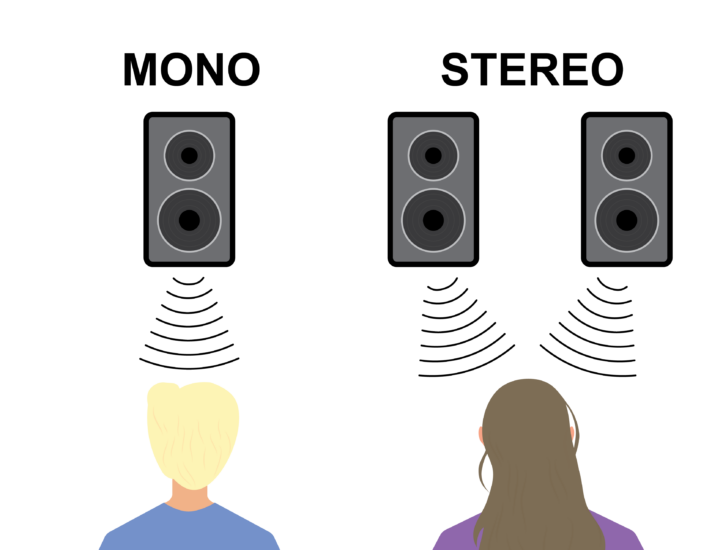
우리가 해결하고자 하는건, 어쨋든 n-channel 이상의 waveform에 대해 평균을 내주어 mono channel로 만드는 것으로 간주할 수 있다.
아래와 같이 해결하면 된다.
import torchaudio
import torch
waveform = './test.wav'
y, sr = torchaudio.load(waveform)
waveform_mono = torch.mean(y, dim=0).unsqueeze(0)
위와 같이 진행하면 waveform_mono는 (1, 100)의 형태로 얻어질 수 있다.
728x90
'딥러닝 > Speech dataset Processing' 카테고리의 다른 글
| 대용량 데이터셋 wget으로 우분투에 한번에 받기 (0) | 2021.10.03 |
|---|---|
| pcm file reading 관련 issue 와 비교 (3) | 2021.09.30 |
| flac dataset wav로 변환 및 downsampling (2) | 2019.12.23 |
| Matlab의 Stft결과와 Python librosa의 Stft결과의 다름 (1) | 2019.08.03 |
| Python Mel-Spectrogram(Mel scaled Spectrogram) 얻기 (9) | 2019.05.09 |