임의의 점이 선택되고, 해당 선을 따라 $0$에서 시간 왜곡 매개 변수 $W$까지의 균일 분포에서 선택한 거리 $w$로 왼쪽 또는 오른쪽으로 warping 함
2. Frequency Masking
주파수 채널 $[f_0,f_0 + f)$ 이 마스킹됨
여기에서 $f$는 0에서 주파수 마스크 매개 변수 $F$까지의 균일한 분포에서 선택됨
$f_0$은 $[0, v-f)$에서 선택되며, 여기에서 $v$는 주파수 채널의 수임 (80차원 mel-spectrogram이 주로 사용되므로 80이 해당됨)
3. Time Masking
연속 시간 단계 $[t_0, t_0+t)$가 마스킹됨
$t$는 0에서 시간 마스크 매개 변수 $T$까지의 균일한 분포에서 선택됨
$t_0$은 $[0,\tau-t)$에서 선택됨
위에서부터 아래로, log-mel spectrogram 입력, time warping, frequency masking, time masking 적용된 그림
4. Augmentation Policy
Frequency masking과 Time maksing을 결합하여 아래의 그림과 같이 4개의 새로운 정책이 도입됨
LB, LD, SM 및 SS 정책
여기에서,
- $W$는 시간 왜곡 매개 변수
- $F$는 주파수 마스킹 매개 변수
- $m_F$: 적용된 주파수 마스킹 수
- $T$: 시간 마스킹 매개 변수
- $m_t$: 적용된 시간 마스킹 횟수
이에 따라 적용된 증강 스펙트럼 결과는 아래의 그림과 같음
위에서부터 아래로, 원본 log mel-spectrogram, LB 적용 결과, LD 적용 결과
Experimental setup and results
Setup
- 80-dimensional log-mel spectrogram 사용
- Encoder layer에서 stride size가 2 인 32 개 채널이 있는 3x3 컨볼 루션의 2 개 레이어가 포함되어 총 시간 감소 계수인 $r$ factor를 4로 설정함
- Convolutional layer위의 Encoder에는 Bi-LSTM (LAS-4-1024) layer 4 개가 포함됨
- 최대 학습률을 $1e−3$으로, batch_size를 512로, 32 개의 Google Cloud TPU를 사용하여 학습하였음
results
- 논문 출판 당시 SpecAugment를 이용하여 SOTA 달성함
Switchboard 300H WER results
SpecAugment는 overfitting 문제를 underfitting 문제로 변환함 - 아래 그림의 네트워크의 learning curve에서 볼 수 있듯이 훈련 중 네트워크는 training dataset의 loss 및 WER뿐만 아니라 augmented dataset에 대해서도 learning시 적합하지 않은 것처럼 보임
- 이것은 네트워크가 training dataset에 과도하게 맞추는 경향이 있는 일반적인 상황과는 완전히 대조적임
- 이를 통해 Data augmentation은 과적합 문제를 과소 적합 문제로 변환함을 보임
시간 왜곡이 기여하지만 성능을 향상하는 주요 요인은 아님 - 시간 왜곡, 시간 마스킹 및 주파수 마스킹이 각각 해제된 세 가지 훈련 결과를 제공하였음
- 시간 왜곡의 효과는 작다고 밝힘 - SpecAugment 작업에서 시간이 오래 걸리고 가장 영향력이 적은 Time warping은 GPU&CPU&Memory를 고려하여 가장 첫 번째로 삭제할 법한 문제로 밝힘
Label smoothing의 효과
- 레이블 평활화로 인해 훈련이 불안정해질 수 있음
- LibriSpeech 학습 시 학습률이 점차 감소할 때, Label smoothing과augmentation이 함께 적용되면 training이 불안정해짐을 밝힘 - 따라서 LibriSpeech에 대한 학습률의 초기 단계에서만 레이블 스무딩을 사용했다고 함
Conclusion & Take Away
- Time warping은 모델 성능을 많이 향상하지 못하였음 - Label smoothing은 훈련을 불안정하게 만듦 - 데이터 augmentation은 over-fitting 문제를 under-fitting 문제로 변환함 - 증강이 없는 모델은 훈련 세트에서 거의 완벽하게 수행되는 반면 다른 데이터 세트에서는 유사한 결과가 수행되지 않음을 알 수 있음 ==> Augmentation이 일반화에 기여함을 알 수 있음
Reference
[1] Park, Daniel S., et al. "SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition}}." Proc. Interspeech 2019 (2019): 2613-2617.
[2] Chan, William, et al. "Listen, attend and spell: A neural network for large vocabulary conversational speech recognition." 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2016.
Neural networks는 비선형 특성 변환과 로그-선형 분류기의 결합 모델로 간주될 수 있기 때문에 Neural network의 입력 특성은 작은 섭동(Perturbation: 다른 행성의 힘을 무시하고 타원방정식을 구한 뒤, 섭동에 의해 어떻게 변하는지 계산함. NN으로 따지면 outlier 학습 정도가 되지 않을까?)에 덜 민감함 차별적 내부 표현 (robustness representation)을 추출할 수 있다면, 음성 인식 정확도를 향상 시킬 수 있음
그러나 테스트셋이 학습셋과의 분포가 매우 다르면 NN의 성능이 저하 될 수 밖에 없음. 즉, NN은 학습셋과 상당히 다른 샘플이 테스트셋으로 들어오게 되면 좋은 결과를 낼 수 없음 (extrapolate 할 수 없음)
그러나 훈련셋의 분포와 테스트 셋의 분포가 비슷하다면, NN에서 학습한 내부 기능은 화자 차이, 대역폭 차이 및 환경 왜곡과 관련하여 상대적으로 안정적인 인식률을 보유할 수 있음
즉, 위처럼 해결하고자, 환경 소음에 의해 왜곡 된 narrow 및 wide band의 음성 및 음성 혼합에 대한 일련의 recognition 실험을 사용하여 이러한 문제를 해결하려는 것이 목적
(Wide band: 16kHz, narrow band: 8kHz)
Method 혼합 대역폭 ASR 연구 (mixed-bandwidth ASR study)
- 일반적인 음성 인식기는 8kHz로 녹음 된 narrow band 음성 신호 또는 16kHz로 녹음된 wide band 음성 신호로 훈련되지만, 단일 시스템이 narrow/wide band 음성, 즉 혼합 대역폭 ASR을 모두 인식할 수 있다면 유리하다고 가정
- 아래의 그림은 혼합 대역폭 ASR 시스템의 아키텍처이며, 이를 기반으로 동적 기능과 함께 29차원의 멜 스케일 로그 필터 뱅크 출력을 진행
NN을 사용한 mixed-bandwidth 음성 인식 그림
- 29 차원 필터 뱅크는 두 부분으로 구성 - 처음 22 개 필터는 0-4kHz에 걸쳐 있고 마지막 7 개 필터는 4-8kHz에 걸쳐 있으며, 더 높은 필터 뱅크에있는 첫 번째 필터의 중심 주파수는 4kHz임
- 음성이 광대역이면 29 개의 모든 필터에 관찰 된 값이 있지만, 음성이 협대역이면 고주파 정보가 캡처되지 않았으므로 최종 7 개의 필터가 0으로 설정됨
- 혼합 대역폭 훈련은 누락 된 대역을 명시 적으로 재구성 할 필요없이 여러 샘플 속도를 동시에 처리함
- 저자는 16kHz와 8kHz로 샘플링 된 데이터로 음향 모델을 훈련하며, 8kHz 입력에 대한 기능을 계산할 때 high-frequency의 log mel 대역은 0으로 설정
Experimental setup and results
데이터셋: mobile voice search (VS) corpus
- VS1: 72 시간의 16kHz training set
- VS2: 197 시간의 16kHz training set
- VS-T: 9562개의 발화, 총 26757개의 단어
- 8kHz인 narrow band의 훈련 및 테스트 데이터셋은 16kHz인 wide band를 다운 샘플링하여 얻음
협대역 훈련 데이터가 있거나 없는 광대역(16k) 및 협대역(8k) 테스트 세트의 WER(%).
결과
- 위의 표는 NN이 8kHZ 음성 유무에 관계없이 훈련되었을 때 16kHz 및 8kHz 테스트 세트에 대한 WER을 보임
- 이 표에서 모든 훈련 데이터가 16kHz이면 NN이 16kHz VS-T (27.5 % WER)에서 잘 수행되지만, 8kHz VS-T (53.5 % WER)에서는 매우 열악함
- 그러나 훈련 셋 중 VS-2를 8kHz로 변환하고 mixed-bandwidth 데이터 (두 번째 행)를 사용하여 동일한 NN을 훈련하면 NN은 16kHz 및 8kHz 음성 모두에서 잘 수행됨을 보임
Conclusion
- 잡음과 유사하게 mixed-bandwidth 훈련은 여러 샘플링 속도로 일반화하는데 도움이 됨
- 또한, DNN이 음성 변동성의 두 가지 중요한 소스인 화자 변동성과 환경 왜곡에 비교적 invariant한 표현을 학습할 수 있음을 보였음
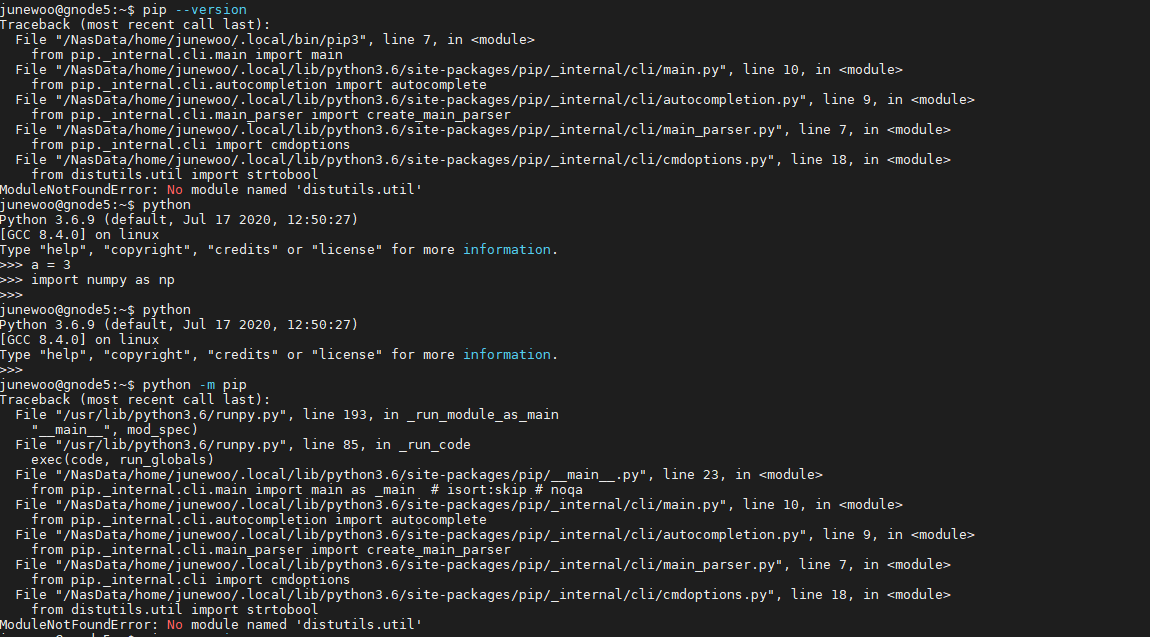
Batch_size에 따라, 혹은 미리 데이터를 전처리 할 때, sequential 한 데이터셋에 대해 maximum length를 구해야 할 때가 있다.
이후에 Zero padding 까지 해주어야 하는데, 이번 글에서는 maximum length 구하는 것만 다룬다.
아주 직관적이고 쉬운 코드로 가겠다.
import numpy as np
a = np.random.rand(1, 7)
b = np.random.rand(1, 20)
c = np.random.rand(1, 3)
d = np.random.rand(1, 50)
print('a {}, a shape {}'.format(a, a.shape))
print('b {}, b shape {}'.format(b, b.shape))
print('c {}, c shape {}'.format(c, c.shape))
print('d {}, d shape {}'.format(d, d.shape))
dataset = list()
dataset.append(a)
dataset.append(b)
dataset.append(c)
dataset.append(d)
2차원 데이터에 대해, 예를 들어 text 라고 가정하겠다. ['안', '녕', '하', '세', '요'] 라고 되어 있는 데이터셋은 (1,5)의 shape을 갖는다. 이 데이터셋들을 전체로 모아서 처리할 땐 glob 등을 사용하지만, 예시에서는 4개를 임의로 세팅하고 dataset.append 을 이용하여 7, 20, 3, 50의 길이를 갖는 데이터셋을 임의적으로 만들었다.
def target_length_(p):
return len(p[0])
length = list()
for i in range(len(dataset)):
i_th_len = target_length_(dataset[i]) # return length
length.append(i_th_len)
max_length = np.argmax(length) # find maximum length
print(max_length) # max_length index
maximum_length = length[max_length]
print(maximum_length)
그 뒤, 데이터셋을 매 번 반복하여 위의 target_length_ 함수를 이용해서 원하는 차원의 length를 구하면 된다.
2차원, 3차원, 4차원 등 원하는대로 설정하여 maximum length 값을 얻어 올 수 있다.
import numpy as np
a = np.random.rand(1, 7)
b = np.random.rand(1, 20)
c = np.random.rand(1, 3)
d = np.random.rand(1, 50)
print('a {}, a shape {}'.format(a, a.shape))
print('b {}, b shape {}'.format(b, b.shape))
print('c {}, c shape {}'.format(c, c.shape))
print('d {}, d shape {}'.format(d, d.shape))
dataset = list()
dataset.append(a)
dataset.append(b)
dataset.append(c)
dataset.append(d)
def target_length_(p):
return len(p[0])
length = list()
for i in range(len(dataset)):
i_th_len = target_length_(dataset[i]) # return length
length.append(i_th_len)
max_length = np.argmax(length) # find maximum length
print(max_length) # max_length index
maximum_length = length[max_length]
print(maximum_length)
Tensorflow는 pytorch의 dataloader처럼 queue를 사용하여, 전체 데이터셋을 가져온 뒤 그것을 batch 만큼 쪼개서 하는 것이 살짝 번거롭다.
즉 이말을 다시 풀어보면, pytorch에서는 dataloader를 사용하여 여러 queue를 사용해서 batch 만큼 데이터셋을 가져온 뒤, 이것을 tensor로 바꿔서 model에 넣는 것이 수월한데 비해
Tensorflow에서는 tf.data.Dataset.from_tensor_slices 를 사용해서 전체 데이터셋을 가져오는 예제가 많다.
게다가 대용량 데이터셋을 사용하게 될 경우, 데이터셋의 총 사이즈가 3GB 정도가 넘어가면 tensorflow 는 API 관련 오류가 생기면서 data load가 안 될 때가 있다.
근 3일 정도 고생하면서 찾아본 정보들을 합쳐서, 음성 데이터셋의 stft 한 결과인 2차원 데이터셋을 tfrecord로 저장하는 방법을 소개한다.
# 전처리
음성(.wav)파일 모두에 대해, 2차원 stft를 얻었다고 가정하고 진행하겠다.
stft를 바꾸는 방법은 이 블로그 내에 있다.
import tensorflow as tf
print(tf.__version__)
import os
import librosa
from glob import glob
import numpy as np
list_inp = sorted(glob('/your/input/dataset/*/*.npz'))
list_tar = sorted(glob('/your/target/dataset/*/*.npz'))
print(len(list_inp))
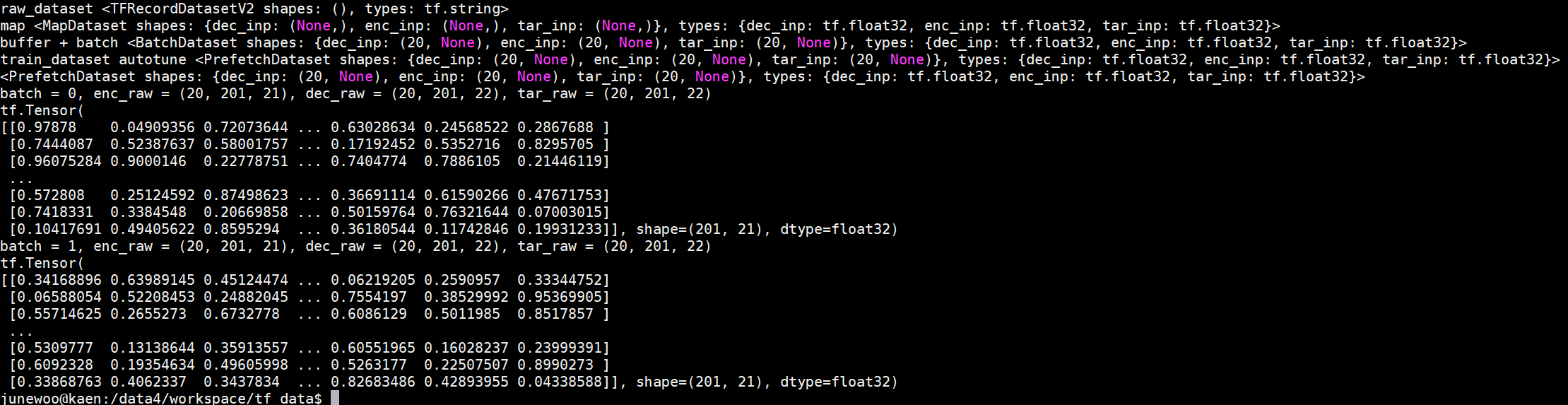
위의 코드는 모든 음성 파일을 .npz 라는 numpy 형태의 data format으로 미리 저장해둔 상태이고, 이것을 glob으로 가져오는 모습이다. Seq2Seq 모델의 Encoder input인 list_inp와 Decoder input, Real value input인 list_tar의 전체를 가져온다.
2d numpy 값을 그대로 value=feature1 를 해주면, 오류가 생긴다. 이를 찾아보게 되면, tensorflow에서의 FloatList는 1차원 값만 넣어줄 수 있기 때문이다. 그러므로, flatten()을 하여 넣어준다.
나 같은 경우 input과 target을 모두 maximum legnth를 구하고 zeropadding하여 shape을 아는 상태이지만, 만약 데이터셋이 모두 다를 경우 feature['shape'] = tf.train.Feature(int_list=tf.train.IntList(value=feature1.shape) 을 대입하여 나중에 데이터셋을 실제로 model에 넣을 때 shape을 기억하여 변환할 수 있다.
그다음 features = tf.train.Features(feature=feature)를 통해 tensorflow의 tensor로 변환해주고,
example 또한 마찬가지로 변환해준다.
serialized = example.SerializeToString() 을 통하여 binary? 로 변환해준다. 마지막으로 tf.records 파일을 write 해주는 writer.write(serialized)를 해주면 끝난다.
이것을 batch size만큼 해준다...
전체코드는 아래와 같다.
# 전체 코드
import tensorflow as tf
print(tf.__version__)
import os
import librosa
from glob import glob
import numpy as np
def serialize_example(batch, list1, list2):
filename = "./train_set.tfrecords"
writer = tf.io.TFRecordWriter(filename)
for i in range(batch):
feature = {}
feature1 = np.load(list1[i])
feature2 = np.load(list2[i])
print('feature1 shape {} feature2 shape {}'.format(feature1.shape, feature2.shape))
feature['input'] = tf.train.Feature(float_list=tf.train.FloatList(value=feature1.flatten()))
feature['target'] = tf.train.Feature(float_list=tf.train.FloatList(value=feature2.flatten()))
features = tf.train.Features(feature=feature)
example = tf.train.Example(features=features)
serialized = example.SerializeToString()
writer.write(serialized)
print("{}th input {} target {} finished".format(i, list1[i], list2[i]))
list_inp = sorted(glob('/your/input/dataset/*/*.npz'))
list_tar = sorted(glob('/your/target/dataset/*/*.npz'))
print(len(list_inp))
serialize_example(len(list_inp), list_inp, list_tar)
input, target 각각 8백만개 씩 있는데, 이것들이 과연 tfrecords를 통해 저장하였을 때의 공간적 이득과, 시간이 얼마나 걸리는지 체크해봐야겠다.
체크 해본 뒤, Tfrecord 파일을 다시 원래대로 음성 데이터 spectrogram으로 복구하는 것을 이번주내로 올릴 예정이다.