본 논문의 제목은 Neural Discrete Representation Learning [1] 이며, vector quantizing 기법, codebook 등을 사용하여 continuous한 data를 discrete하게 representation 추출이 가능한 기법을 제안한 논문이다. 본 논문에서는 clustering 기법으로 해당 벡터를 분류하였지만, 이 논문 외에도 Gumbel-Softmax [2] 등을 사용하여 더 higher 한 dimension의 codebook을 사용할 수 있음을 밝힌다.
Overview
- 연속적 (continuous) 데이터 특성에서 이산 (discrete)으로 학습
- auto-encoder 혹은 VAE의 bottleneck 부분인 latent space에서 뽑힌 latent vector들을 codebook 형태로 embedding 한 후, 제한된 수의 코드북 vector를 이용하여 data를 reconstruction
Proposed method
VQ-VAE model architecture
Learning from Continuous to Discrete
- 모델은 입력 x로부터 받아 인코더를 통해 출력 ze(x)를 생성함
- 이 때, discrete latent variable z는 shared embedding space인 e로부터 가장 가까운 neighborhood와의 distance 계산에 의해 결정됨. 즉 가장 가까운 vector로 결정
- 여기에서 e인 embedding space를 codebook으로 불리우며, e∈RK∗D이며, 여기에서 K는 discrete latent space의 size가 됨 (즉, K-way categorical)
- 그림에서 D는 각각의 latent embedding vector인 ei의 차원 수
- 종합적으로, K개의 embedding vector가 존재하며, 이를 수식으로 나타내면 ei∈RD,i∈1,2,...,K가 됨
본 논문의 제목은 wav2vec: Unsupervised Pre-Training for Speech Recognition [1] 이며, CPC 기법을 사용하여 unsupervised로 representation learning을 제안한 논문이다.
Overview
Raw audio representation을 unsupervised로 학습하여 음성 인식을 위한 사전 교육을 제안함 - 다량의 unlabeled 오디오 데이터에 대해 학습되며, 결과 representation 은 AM 학습을 개선하는데 사용 - 이 모델은 simple multi-layer CNN으로 구성되어 있으며, Negative contrastive loss 기반의 이진 분류 task를 통해 사전학습 됨
- Contrastive loss 사용
Proposed method
- 오디오 신호가 입력으로 주어지면 모델을 최적화하여 주어진 신호 context에서 향후 샘플 예측 - CPC처럼, raw waveform 샘플 𝑥를 feature representation 𝑧로 인코딩함
- 이후 암시적으로 밀도 비율 p(zi+k|zi,...,zi−r)p(zi+k)를 모델링하여 데이터 분포 p(x)를 정확하게 모델링 함
Encoder
1) Encoder는 raw waveform을 latent space에 embedding 함
Encoder part
- Raw audio sample xi∈X가 주어지면, 5-layer CNN으로 parameterized된 encoder 네트워크 f:X↦ Z 를 적용함
- 커널 크기 [10, 8, 4, 4, 4]와 strides [5,4,2,2,2]로 적용
2) Encoder의 출력은 16kHz 오디오의 약 30ms를 인코딩 - 이로 인해 Feature representation 𝑧𝑖∈𝑍임 - CNN-encoder를 통과한 striding 결과는 10ms마다 representation 𝑧𝑖로 됨 - Causal convolution with 512개 채널, group normalization [2], ReLU
3) 2개의 추가 linear transformation 사용 (Large model)
4) Group normalization - Single normalization group을 사용하는 group normalization와 동일한 각 샘플에 대해 특성 및 시간 차원에서 모두 정규화 함 - 입력의 스케일링과 오프셋에 변하지 않는 정규화 체계 사용
Context network
- Contextnetwork $g:Z$↦$C$를 encoder의 출력에 적용
Context network part
- 다중 latent representation zi,...,ziv를 receptive field 크기 v에 대한 single contextualized 된 tensor ci=g(zi,...,ziv) 로 변환함
- Kernel size 3, stride가 1인 9개의 CNN layer로 구성
- 총 수용 필드는 약 210ms
- Causal convolution with 512개 채널, group normalization, ReLU로 구성
Large model - Kernel size가 증가하는 12개의 계층(2,3,…,13)으로 구성된 large context network도 실험 - 이럴 경우 aggregator에 skip-connections 도입 - 마지막 context network 계층의 총 수용 필드는 약 810ms
Objective, Loss
1) Objective
- 각 단계에 대한 Contrastive loss를 최소화하여 proposal 분포 pn에서 추출한 샘플 ˆz으로부터 향후 k=1,...,K단계의 샘플 zi+k를 구별하도록 모델을 훈련함
- ci에 적용되는 각 step k에 대해 단계별 affine transformation인 hk(ci) = Wkci+bk를 적용
2) Loss
- L=ΣKk=1Lk를 최적화하여, 다른 단계 step에 대해 식 (1)을 합산
- 각 오디오 시퀀스에서 추출된 것을 uniform 하게 선택하여, 10개의 Negative sample을 샘플링 후 예상치 추정
- 즉, proposal 분포인 pn(z)=1T가 됨 (T는 오디오 시퀀스 길이, λ를 Negative로 설정)
- 기법은 CPC와 같음
3) Fine-tuning
- 훈련 후, AM에 log-mel spectrogram 대신 context 네트워크로부터 생성된 representation인 ci를 사용
Experiments
1) Phoneme recognition on TIMIT - WSJ92 81시간, LibriSpeech clean 80시간, LibriSpeech 960시간 모두 pre-training (시간 별 비교)
2) 기준 AM - Log-mel spectrogram 25ms window, 10ms overlap
- Wav2letter ++ toolkit [3] --> AM 교육 및 평가를 위해 사용 - TIMIT 평가를 위해, character-based wav2letter++ setup - 7 consecutive blocks of CNN (kernel size 5 with 1,000 channels) - PReLU 비선형 및 0.7 dropout rate 사용 - 최종 representation: 39-dimensional phoneme probability, 표준 영어 알파벳,아포스트로피 및 마침표,두 개의 반복문자(ann-> an1)및 단어 경계로 사용되는 침묵토큰등을포함하여31개의자소에대한 확률 예측
4) 오디오 시퀀스 처리 - 오디오 시퀀스는 길이별로 그룹화 되며, 각 프레임은 최대 150k frame 크기 (150,000 == 10초 이내) - 최대 150k 프레임 크기 또는 배치에서 가장 짧은 시퀀스의 길이 중 더 작은 길이로 cut - 오디오 시퀀스의 시작 또는 끝에서 음성 신호를 제거함 - 매 epoch 마다 다시 샘플링함 - 즉, 증강 기법 중 하나로 볼 수 있으며, 훈련 데이터의 평균 25%를 제거함
5) Pre-training 학습 관련
- SGD with learning rate 5.6 + gradient clipping
- 1,000 epochs with batch size of 64 audio sequences
- V100GPUx8EA
- 4-gram LM로 체크 포인트 평가 후 조기 종료 사용
6) Downstream task (TIMIT)
- Train on si284, validate on nov93dev and test on nov92
- All training samples time: around three hours
- Learning rate 0.12, momentum 0.9
- Training 1,000 epochs with batch size of 16 audio sequences
7) Decoding 기법
- AM 방출을 디코딩하기 위해, WSJ LM 전용 데이터에 대해서만 학습 된 별도의 LM + lexicon 사용 - 4-gram KenLM LM, word-based CNN LM, character-based CNN LM 사용 - 아래의 식을 최대화하기 위해 Beam search decoder를 사용하여 context 네트워크 𝑐 또는 log-mel filterbank의 출력에서 단어 시퀀스 𝑦를 디코딩 함
maxyfAM(y|c)+α+logpLM(y)+β|y|−γΣTi=1[πi=′|′]
- fAM(y|C)는 AM, pLM은 LM, π=π1,...,πL은 y의 문자
- Hyperparameter인 α,β,γ는 AM, 단어 패널티 및 silence 패널티에 대한 가중치 - WSJ를 디코딩하기 위해 random search를 사용하여 hyperparameter들을 조정하고, optimized 된 이들의 설정으로 AM 방출 - 단어 기반 LM에 대해 beam size 4,000 및 beam score threshold 250을 사용 - 문자 기반 LM에 대해 beam size 1,500 및 beam score threshold 40을 사용
Results
1) Pre-training for the WSJ benchmark
wav2vec results, comparison with the other papers
- WSJ의 오디오 데이터 (레이블 X), clean LibriSpeech (80h), 960 LibriSpeech을 이용한 pre-train - Log-mel filterbanks 대신 context 네트워크 출력 c를 AM에 제공 - 데이터를 더 많이 사용하여 pre-train할 수록 WSJ 벤치마크에서 더 나은 정확도로 이어짐 - Pre-train된 representation은 log-mel filterbanks에 대해 훈련된 character-based 기준에 비해 향상됨 - 당시, SOTA였던 character-based의 Deep Speech2 보다 향상: [4](그림 내 [35])와 비교할 때, 음소 기반 모델만큼 성능이 뛰어남
2) Pre-training for the WSJ benchmark Pre-trained representation의 영향
effective of amount of dataset that used in pre-training
- 약 8시간의 label이 있는 데이터만 사용하여 scratch-training할 경우 nov92에서 36%의 WER 획득 - WSJ의 오디오 데이터에 대한 pre-training은 훨씬 더 큰 LibriSpeech에 비해 성능이 나쁨 - 즉, 더 많은 데이터에 대한 사전 훈련이 좋은 성능을 내는 것을 확인 - 데이터가 증가될수록 성능이 좋아지지만, unlabeled의 LibriSpeech로 pre-training되어 fine-tuning한 모델보다 좋지 못함
3) Pre-training for TIMIT
Results
results of TIMIT downstream task
- TIMITtask에서는 dropout rate가 높은 7-layer wav2letter ++ 모델 사용
- 제안한 unlabeled data로 부터 representation 학습하여 fine-tuning한 모델이 PER에서 가장 좋은 성능을 얻었음
Ablation
1) LibriSpeech의 80시간 pre-training에 대한 분석
effective of number of negative samples
- Table3은 Negative 샘플의 수가 늘어날 수록 도움이 되지만, 최대 10개가 한계
- 훈련 시간이 증가될수록 성능이 정체됨
- Negative 샘플의 수가 증가함에 따라 Positive 샘플의 훈련 신호가 감소하기 때문임
2) 오디오 시퀀스 cutting을 통한 데이터 증강 효과 분석
analysis of crop sizes
- 배치를 생성할 때 사전 정의된 최대 길이로 시퀀스 cutting - 150k frame의 자르기 크기가 최상의 성능임을 확인 - 최대 길이를 제한하지 않으면 평균 시퀀스 길이가 약 207k이 되어 정확도가 가장 낮음
3) 미래 예측 step - K=12이상일 경우 성능 향상 X - 훈련 시간만 늘어나고, 성능 개선 없음
Summary & Major take away
- Fully CNN을 사용하여 ASR에 unsupervised pre-training을 처음 적용하였음 - 이 방식은 fine-tuning시 labeled된 데이터를 적게 사용함에도 불구하고 당시 SOTA였던 character-based ASR 모델인 Deep Speech 2를 능가하였음 - Pre-training을 위한 데이터가 많을수록 성능이 향상 됨
- 성능 차이가 CPC에 비해 너무 크게 나기 때문에, 조금 못 미더운 부분이 있다고 개인적으로 생각함
[1] Schneider, Steffen, et al. "wav2vec: Unsupervised Pre-Training for Speech Recognition." Proc. Interspeech 2019 (2019): 3465-3469.
[2] Wu, Yuxin, and Kaiming He. "Group normalization." Proceedings of the European conference on computer vision (ECCV). 2018.
[3] Collobert, Ronan, Christian Puhrsch, and Gabriel Synnaeve. "Wav2letter: an end-to-end convnet-based speech recognition system." arXiv preprint arXiv:1609.03193 (2016).
[4] Hadian, Hossein, et al. "End-to-end Speech Recognition Using Lattice-free MMI." Interspeech. 2018.
본 논문의 제목은 Representation learning with contrastive predictive coding [1] 이며, CPC라는 unsupervised learning 기법을 제안하였다.
Overview
- 이 논문은 high-dimensional 데이터에서 유용한 representation을 추출하기위한 unsupervised learning 접근법을 제안하였음 - 강력한 auto-regressive 모델을 사용하여 latent space에서 추출된 z를 이용하여 미래를 예측하는 representation 학습법 제안 - 미래 샘플을 예측할 때 가장 유용한 정보를 얻기 위해 latent spece를 유도하는 확률적 contrastive loss 사용
Mutual information이란?
Mutual information (figure from Oord)Mutual information - Contrastive (figure from Oord)
Mutual information - Contrastive loss (figure from Oord)
Background
- 지도 학습 기반의 end-to-end 네지도 학습 기반의 end-to-end 네트워크는 AI를 발전시키는 것에 성공하였지만, 하지만 데이터 효율성, 견고성 또는 일반화와 같은 많은 과제가 남아있음
- 이를 위해 High-level representation 학습이 가능한 Unsupervised 기법이 필요하지만, raw level observation에서 high-level representation 모델링이 어렵고, 이상적인 표현이 무엇인지 명확하지 않으며, 특정 데이터 양식에 대한 추가 감독이나 전문화없이 이러한 표현을 배울 수 있는지 명확하지 않음
- Unsupervised 학습을 위한 가장 일반적인 전략 중 하나는 미래를 예측하는 것이며, predict coding 아이디어는 데이터 압축을 위한 신호 처리에서 사용된 오래된 기술 중 하나임
- 또한, 미래나 contextual 정보를 예측하는 unsupervised learning 기법을 제안하고자 함
- 실제로 이러한 아이디어를 사용하여 이웃 단어를 예측하여 단어 표현을 학습한 사례가 있음 (Word2Vec) [2]
Proposed method
1) Conditional 예측 모델링을 쉽게 하기 위해 latent embedding space로 high-dimensional data를 압축 - 이 latent space에서 강력한 autoregressive model을 사용하여 미래에 많은 steps을 예측함
- 즉, 고차원 데이터 간에 shared information을 인코딩한 mutual information을 얻기 위해 representation을 학습함
2) Noise-Contrastive Estimation[3]에 의존한 loss 함수
- 자연어 모델에서 word embedding을 학습하는데 사용된 것과 유사한 방식으로, loss 함수에 대해 Noise-Contrastive Estimation에 의존하여 전체 모델이 end-to-end 학습 가능하도록 제안
3) 결과 모델인 Contrastive Predictive Coding (CPC)를 다양한 task에 적용 - 이미지, 음성, 자연어 및 강화 학습
Noise-Contrastive Estimation
1. NCE
1) CBOW와 Skip-Gram 모델에서 사용하는 비용 계산 알고리즘
- 전체 데이터셋에 대해 SoftMax 함수를 적용하는 것이 아니라 샘플링으로 추출한 일부에 대해서만 적용하는 방법
- k개의 대비되는(contrastive) 단어들을 noise distribution에서 구해서 (몬테카를로) 평균을 구하는 것이 기본 알고리즘
Hierarchical SoftMax와 Negative Sampling 등 여러 가지 방법 존재
- 일반적으로 단어 개수가 많을 때 사용하고, NCE를 사용하면 문제를 (실제 분포에서 얻은 샘플=Positive)과 (인공적으로 만든 잡음 분포에서 얻은 샘플=Negative)을 구별하는 이진 분류 문제로 바꿀 수 있게 됨
2) Negative Sampling에서 사용하는 목적 함수는 결과값이 최대화될 수 있는 형태로 구성
- 현재(목표, target, positive) 단어에는 높은 확률을 부여하고, 나머지 단어(negative, noise)에는 낮은 확률을 부여해서 가장 큰 값을 만들 수 있는 공식 사용
- 특히, 계산 비용에서 전체 단어를 계산하는 것이 아니라 선택한 k개의 noise 단어들만 계산하면 되기 때문에 효율적
2. Hierarchical SoftMax
1) CBOW와 Skip-Gram 모델은 내부적으로 SoftMax 알고리즘을 사용해서 계산 진행함
- 모든 단어에 대해 계산 및 normalization을 진행하는데, 많은 시간이 걸리는 단점 존재
- 이를 해결하기 위한 Hierarchical SoftMax와 Negative Sampling 알고리즘이 있음
2) Hierarchical SoftMax
- Hierarchical SoftMax 알고리즘은 계산량이 많은 SoftMax function을 빠르게 계산가능한 multinomial distribution 함수로 대체함
- Word2Vec 논문에서는 사용 빈도가 높은 단어에 대해 짧은 경로를 부여함
3. Negative Sampling
1) SoftMax 알고리즘을 몇 개의 샘플에 대해서만 적용하는 알고리즘
- 전체 데이터로부터 일부만 뽑아서 SoftMax 계산을 수행하고 normalization을 진행함
- 이때 현재(목표) 단어는 반드시 계산을 수행해야 하기 때문에 Positive Sample이라 부름
- 나머지 단어를 Negative Sample이라 부름
2) Negative Sampling에서는 나머지 단어에 해당하는 Negative Sample 추출 방법이 핵심
- 일반적으로 샘플링은 ‘Noise Distribution’을 정의하고 그 분포를 이용하여 일정 개수를 추출함
즉 정리해보면,
CPC = 미래 관찰 예측(예측 코딩) + 확률적 대비 손실의 결합 으로 볼 수 있음
이를 통해,
- 오랜 시간 동안 data observation의 mutual information을 최대화 할 수 있음 - 여러 시간 간격으로 떨어져 있는 데이터 포인트들에서 shared information을 인코딩하여 representation 학습 - 이러한 feature를 ‘Slow Features’라고 부르며, 이는 시간이 빠르게 지나도 변하지 않는 feature를 의미함 - E.g., 오디오 신호에서 말하는 사람, 비디오 내의 흐름 등
Model architecture
1) 비선형 인코더 genc
- 해당 time step t를기준으로 진행되며, 이후의 값들을 사용하여 예측하지 않음
- 관측치 xt인 input sequence를 zt=genc(xt)로 매핑함
- 이를 통해, 잠재적으로 더 lower한 temporal resolution으로 변경됨
CPC Encoder
2) Autoregressive model gar
- Latentspace의 현재 시간 t를 포함한 이전의 모든 값들인 z≤t에 대해 요약
- 이후 Context latent representation인 ct=gar(z≤t)를 생성
CPC context nextwork
- 이때, 생성 모델 pk(xt+k|ct)를 사용하여 미래 관측치인 xt+k를 직접 예측하지 않음
- 대신 다음과 같이 xt+k 와 ct사이의 mutualinformation을 보존하는 식(1)을 활용하여 density 비율을 모델링 함
I(x;c)=Σx,cp(x,c)logp(xt+k|ct)p(xt+k)…(1)
fk(xtk,ct)∝p(xt+k|ct)p(xt+k)…(2)
- 식(2)인 밀도비율 $f$ 는 정규화 되지 않을 수 있으므로, log-bilinear model을 적용함
fk(xt+k,ct)=exp(zTt+kWkct)...(3)
- 해당 논문에서, linear transformation인 Wkct 는 모든 단계 k에 대해 다른 Wk를 갖는 예측에 사용됨
- 혹은 비선형 네트워크 또는 반복 신경망으로 사용 가능
- Density ratio f(xt+k,ct) 와 인코더로 ztk를 추론함으로써 모델이 고차원 분포인 xtk를 모델링 하지 않도록 함
- 이 때, p(x) 혹은 p(x|c) 를 직접 평가할 수는 없지만, 위의 분포를 Noise-Contrastive Estimation 혹은 Importance Sampling 방법으로 평가함
- 목표인 Positive 값과 무작위로 샘플링 된 Negative 값의 비교를 기반으로 평가함
- 이를 위해 InfoNCE loss 사용!
3) Downstream task
zt 및 ct 중 하나를 downstream 작업에 대한 representation 으로 사용
- Autoregressive model 출력인 ct는 과거의 extra context가 유용할 경우 사용 (음성 인식, phoneme, speech 등)
- Extra context가 필요하지 않은 다른 경우, zt 를 사용하는 것이 유용 (비전, 이미지 등)
논문에서는 단순화를 위해,
- Encoder: Strided CNN with ResNet blocks
- Decoder: GRU
을 사용하였고, Masking CNN, Self-attention 등 사용하는 것을 권장
4) InfoNCE loss
- Encoder와 Autoregressive model 모두 NCE 기반의 Loss로 최적화 되며, 이를 논문에서 InfoNCE라 부름
- p(xt+k|ct) 의 Positive sample 하나와 proposal 분포 p(xt+k)의 N−1 개의 Negative 샘플을 포함하는 N개의 random sample 집합 X=x1,x2,...,xN이 주어지면, 아래의 식을 최적화함
LN = EX[logfkxt+k,ctΣxj∈Xfkxj,ct]...(4)
- 위의 식 loss를 최적화하면 fk(xt+k,ct) 가 식(2)의 density 비율을 추정함
- 식(4)의 loss는 Positive 샘플을 바르게 분류하는 categorical cross-entropy이며, fkΣXfk는 모델의 예측임
- 위 loss에 대한 최적의 확률을 p(d=i|X,ct)라 할때, [d=i]는 샘플 xi의 Positive toavmfdl ehla
- 제안된 분포 p(xt+k)가 아닌 조건부 분포 p(xt+k|ck)에서 샘플 xi를 추출할 확률은 다음과 같음
- 식 (4)에서 f(xt+k,ct)에 대한 최적값은 p(xt+k|ct)p(xt+k) 에 비례하며, 이는 Negative 샘플 수인 N−1과 무관함
Experiments (여기에선 Phoneme recognition에 관해서만 다루겠음)
Using LibriSpeech-100hour train - Kaldi toolkit 및 LibriSpeech1에서 사전 훈련된 모델을 사용하여 강제 정렬된 시퀀스 사용 - 251명의 서로 다른 화자의 speech 포함
Encoder - 입력 음성 16kHz PCM 그대로 입력 받음 - Strides [5,4,2,2,2], filter-sizes [10,8,4,4,4], 512 차원의 ReLU사용 - Downsampling factor가 160이므로, 음성의 10ms마다 특성 벡터가 사용됨
Autoregressive - 256차원의 GRU RNN 사용 - 모든 시간 단계에서 GRU의 출력은 contrastive loss를 사용하여 12 개의 시간 단계를 예측하는 컨텍스트 𝑐로 사용됨 - 음성 길이는 20480으로 fix
Hyperparameters - Adam optimizer, 2e-4 lr - Contrastive loss의 negative sample을 추출하는 Minibatch size 8로 GPU 8개 학습 - 수렴 될 때까지 학습, 대략 300,000 steps 학습
Results
1) Predict latents in the future (Figure 3)
미래 예측 step에 따른 정확도
- Time step으로 미래의 latent를 예측하는 모델의 정확도 - Positive sample에 대한 logit이 Negative sample 보다 더 높은 평균 횟수를 가짐 - 거리가 멀어질수록 waveform 예측 정확도가 떨어짐
2) Phoneme classification (Table 1)
Phoneme recognition 결과
- 모델 수렴 후 전체 데이터 세트에 대한 GRU (256차원), 즉 𝑐_𝑡의 출력을 추출 - Multi-class linear logistic regression classifier 훈련 (downstream) - MFCC, CPC, Supervised 모두 같은 네트워크 구조 - GRU 대신 single hidden layer 사용하였을 경우 72.5%
3) Two ablation studies of CPC (Table 2)
미래 예측 step에 따른 정확도
- Time step의 거리가 멀어질수록 waveform 예측 정확도가 낮지만, 예측하는 미래 step 수가 멀어질수록 음소 분류 정확도가 높아짐 - 모든 샘플이 동일한 스피커로부터 얻어 졌을 경우, 음소 분류 정확도가 높음을 알 수 있음
4) Speaker identification
- 동일한 representation의 linear classifier를 사용하여 251명의 speaker identity 수행 - 단순한 linear classifier로 얻은 우수한 정확도를 통해, CPC는 speaker identity와 음성 콘텐츠를 모두 캡처함을 주장
t-SNE 비교
Speaker identification에 대한 t-SNE 분포
- GRU의 maximum context 크기는 성능에 큰 영향을 미쳤음 - 더 긴 세그먼트는 더 나은 결과를 제공할 수 있음 - 20480개의 wav length (약 1.3초)에 대한 결과임
Summary
Contrastive Predictive Coding
1) 텍스트, 음성, 비디오, 이미지와 같이 정렬된 순서로 표현할 수 있는 모든 형태의 데이터 적용 가능 2) 여러 시간 간격으로 떨어져 있는 데이터 포인트들 xt:t+k 에서 공유되는 정보를 인코딩 - Representation 학습을 통해 Slow features를 얻고 이를 이용하여 미래의 데이터를 예측함 - 현재의 target을 Positive로 두고 noise 등이 포함 된 Negative들을 구별할 수 있는 InfoNCE loss를 사용하여 미래의 데이터를 예측하도록 함 3) 단일 테스크에서 여러 ks를 사용하여 다양한 시간 척도에서 진화하는 feature들을 캡처함 4) xt에 대한 representation을 계산할 때, encoder 네트워크 위에서 실행되는 Autoregressive Network를 사용하여 과거 context 정보를 encoding 할 수 있음 (미래의 것은 사용 X)
Conclusion & Major take away
- 최근 이미지 분야의 Self-supervised 에서 널리 사용되는 Contrastive learning에 대하여 분석해보았음
- 음성에 대해서는 미래 예측 step k 에 대해서 사용하고, 이미지에 대해서는 (sequential 하지 않다 보니) 현재의 sample 및 augmented 된 것들이 아닌 다른 class에 대해 negative sample로 간주하여 학습하는 기법임
- 앞으로 리뷰할 논문 및 최근 트렌드가 해당 내용이므로, 반드시 알고 가야 할 기법이었음
- 더 자세한 내용은 코드 리뷰할 필요가 있음
My appendix
2) Self-supervised learning using contrastive learning (InfoNCE loss), [4]
[4] 논문은 Contrastive Learning에 대해 잘 리뷰한 논문이고, 해당 논문을 참조하면 더 많은 정보를 얻을 수 있을 것 같음
Contrastive learning paradigm [4]Network flow of contrastive [4]Video processing with contrastive learning [4]
Different architecture pipelines for Contrastive Learning [4]Pre-training, fine-tuning of Contrastive learning [4]
Explanation of InfoNCE loss [4]
[1] Oord, Aaron van den, Yazhe Li, and Oriol Vinyals. "Representation learning with contrastive predictive coding." arXiv preprint arXiv:1807.03748 (2018).
[2] Mikolov, Tomas, et al. "Efficient estimation of word representations in vector space." arXiv preprint arXiv:1301.3781 (2013).
[3] Gutmann, Michael, and AapoHyvärinen. "Noise-contrastive estimation: A new estimation principle for unnormalized statistical models." Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics. JMLR Workshop and Conference Proceedings, 2010.
[4] Jaiswal, Ashish, et al. "A survey on contrastive self-supervised learning." Technologies 9.1 (2021): 2.
임의의 점이 선택되고, 해당 선을 따라 0에서 시간 왜곡 매개 변수 W까지의 균일 분포에서 선택한 거리 w로 왼쪽 또는 오른쪽으로 warping 함
2. Frequency Masking
주파수 채널 [f0,f0+f) 이 마스킹됨
여기에서 f는 0에서 주파수 마스크 매개 변수 F까지의 균일한 분포에서 선택됨
f0은 [0,v−f)에서 선택되며, 여기에서 v는 주파수 채널의 수임 (80차원 mel-spectrogram이 주로 사용되므로 80이 해당됨)
3. Time Masking
연속 시간 단계 [t0,t0+t)가 마스킹됨
t는 0에서 시간 마스크 매개 변수 T까지의 균일한 분포에서 선택됨
t0은 [0,τ−t)에서 선택됨
위에서부터 아래로, log-mel spectrogram 입력, time warping, frequency masking, time masking 적용된 그림
4. Augmentation Policy
Frequency masking과 Time maksing을 결합하여 아래의 그림과 같이 4개의 새로운 정책이 도입됨
LB, LD, SM 및 SS 정책
여기에서,
- W는 시간 왜곡 매개 변수
- F는 주파수 마스킹 매개 변수
- mF: 적용된 주파수 마스킹 수
- T: 시간 마스킹 매개 변수
- mt: 적용된 시간 마스킹 횟수
이에 따라 적용된 증강 스펙트럼 결과는 아래의 그림과 같음
위에서부터 아래로, 원본 log mel-spectrogram, LB 적용 결과, LD 적용 결과
Experimental setup and results
Setup
- 80-dimensional log-mel spectrogram 사용
- Encoder layer에서 stride size가 2 인 32 개 채널이 있는 3x3 컨볼 루션의 2 개 레이어가 포함되어 총 시간 감소 계수인 r factor를 4로 설정함
- Convolutional layer위의 Encoder에는 Bi-LSTM (LAS-4-1024) layer 4 개가 포함됨
- 최대 학습률을 1e−3으로, batch_size를 512로, 32 개의 Google Cloud TPU를 사용하여 학습하였음
results
- 논문 출판 당시 SpecAugment를 이용하여 SOTA 달성함
Switchboard 300H WER results
SpecAugment는 overfitting 문제를 underfitting 문제로 변환함 - 아래 그림의 네트워크의 learning curve에서 볼 수 있듯이 훈련 중 네트워크는 training dataset의 loss 및 WER뿐만 아니라 augmented dataset에 대해서도 learning시 적합하지 않은 것처럼 보임
- 이것은 네트워크가 training dataset에 과도하게 맞추는 경향이 있는 일반적인 상황과는 완전히 대조적임
- 이를 통해 Data augmentation은 과적합 문제를 과소 적합 문제로 변환함을 보임
시간 왜곡이 기여하지만 성능을 향상하는 주요 요인은 아님 - 시간 왜곡, 시간 마스킹 및 주파수 마스킹이 각각 해제된 세 가지 훈련 결과를 제공하였음
- 시간 왜곡의 효과는 작다고 밝힘 - SpecAugment 작업에서 시간이 오래 걸리고 가장 영향력이 적은 Time warping은 GPU&CPU&Memory를 고려하여 가장 첫 번째로 삭제할 법한 문제로 밝힘
Label smoothing의 효과
- 레이블 평활화로 인해 훈련이 불안정해질 수 있음
- LibriSpeech 학습 시 학습률이 점차 감소할 때, Label smoothing과augmentation이 함께 적용되면 training이 불안정해짐을 밝힘 - 따라서 LibriSpeech에 대한 학습률의 초기 단계에서만 레이블 스무딩을 사용했다고 함
Conclusion & Take Away
- Time warping은 모델 성능을 많이 향상하지 못하였음 - Label smoothing은 훈련을 불안정하게 만듦 - 데이터 augmentation은 over-fitting 문제를 under-fitting 문제로 변환함 - 증강이 없는 모델은 훈련 세트에서 거의 완벽하게 수행되는 반면 다른 데이터 세트에서는 유사한 결과가 수행되지 않음을 알 수 있음 ==> Augmentation이 일반화에 기여함을 알 수 있음
Reference
[1] Park, Daniel S., et al. "SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition}}." Proc. Interspeech 2019 (2019): 2613-2617.
[2] Chan, William, et al. "Listen, attend and spell: A neural network for large vocabulary conversational speech recognition." 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2016.
Neural networks는 비선형 특성 변환과 로그-선형 분류기의 결합 모델로 간주될 수 있기 때문에 Neural network의 입력 특성은 작은 섭동(Perturbation: 다른 행성의 힘을 무시하고 타원방정식을 구한 뒤, 섭동에 의해 어떻게 변하는지 계산함. NN으로 따지면 outlier 학습 정도가 되지 않을까?)에 덜 민감함 차별적 내부 표현 (robustness representation)을 추출할 수 있다면, 음성 인식 정확도를 향상 시킬 수 있음
그러나 테스트셋이 학습셋과의 분포가 매우 다르면 NN의 성능이 저하 될 수 밖에 없음. 즉, NN은 학습셋과 상당히 다른 샘플이 테스트셋으로 들어오게 되면 좋은 결과를 낼 수 없음 (extrapolate 할 수 없음)
그러나 훈련셋의 분포와 테스트 셋의 분포가 비슷하다면, NN에서 학습한 내부 기능은 화자 차이, 대역폭 차이 및 환경 왜곡과 관련하여 상대적으로 안정적인 인식률을 보유할 수 있음
즉, 위처럼 해결하고자, 환경 소음에 의해 왜곡 된 narrow 및 wide band의 음성 및 음성 혼합에 대한 일련의 recognition 실험을 사용하여 이러한 문제를 해결하려는 것이 목적
(Wide band: 16kHz, narrow band: 8kHz)
Method 혼합 대역폭 ASR 연구 (mixed-bandwidth ASR study)
- 일반적인 음성 인식기는 8kHz로 녹음 된 narrow band 음성 신호 또는 16kHz로 녹음된 wide band 음성 신호로 훈련되지만, 단일 시스템이 narrow/wide band 음성, 즉 혼합 대역폭 ASR을 모두 인식할 수 있다면 유리하다고 가정
- 아래의 그림은 혼합 대역폭 ASR 시스템의 아키텍처이며, 이를 기반으로 동적 기능과 함께 29차원의 멜 스케일 로그 필터 뱅크 출력을 진행
NN을 사용한 mixed-bandwidth 음성 인식 그림
- 29 차원 필터 뱅크는 두 부분으로 구성 - 처음 22 개 필터는 0-4kHz에 걸쳐 있고 마지막 7 개 필터는 4-8kHz에 걸쳐 있으며, 더 높은 필터 뱅크에있는 첫 번째 필터의 중심 주파수는 4kHz임
- 음성이 광대역이면 29 개의 모든 필터에 관찰 된 값이 있지만, 음성이 협대역이면 고주파 정보가 캡처되지 않았으므로 최종 7 개의 필터가 0으로 설정됨
- 혼합 대역폭 훈련은 누락 된 대역을 명시 적으로 재구성 할 필요없이 여러 샘플 속도를 동시에 처리함
- 저자는 16kHz와 8kHz로 샘플링 된 데이터로 음향 모델을 훈련하며, 8kHz 입력에 대한 기능을 계산할 때 high-frequency의 log mel 대역은 0으로 설정
Experimental setup and results
데이터셋: mobile voice search (VS) corpus
- VS1: 72 시간의 16kHz training set
- VS2: 197 시간의 16kHz training set
- VS-T: 9562개의 발화, 총 26757개의 단어
- 8kHz인 narrow band의 훈련 및 테스트 데이터셋은 16kHz인 wide band를 다운 샘플링하여 얻음
협대역 훈련 데이터가 있거나 없는 광대역(16k) 및 협대역(8k) 테스트 세트의 WER(%).
결과
- 위의 표는 NN이 8kHZ 음성 유무에 관계없이 훈련되었을 때 16kHz 및 8kHz 테스트 세트에 대한 WER을 보임
- 이 표에서 모든 훈련 데이터가 16kHz이면 NN이 16kHz VS-T (27.5 % WER)에서 잘 수행되지만, 8kHz VS-T (53.5 % WER)에서는 매우 열악함
- 그러나 훈련 셋 중 VS-2를 8kHz로 변환하고 mixed-bandwidth 데이터 (두 번째 행)를 사용하여 동일한 NN을 훈련하면 NN은 16kHz 및 8kHz 음성 모두에서 잘 수행됨을 보임
Conclusion
- 잡음과 유사하게 mixed-bandwidth 훈련은 여러 샘플링 속도로 일반화하는데 도움이 됨
- 또한, DNN이 음성 변동성의 두 가지 중요한 소스인 화자 변동성과 환경 왜곡에 비교적 invariant한 표현을 학습할 수 있음을 보였음
이번에 리뷰를 진행할 논문은 Parrtron 이라는 논문인데, Google에서 작성한 논문이다. 이전에 리뷰한 논문에서의 저자가 1저자로 작성한 논문이다. https://arxiv.org/abs/1904.04169 여기에서 확인할 수 있다.
Abstract & Intro
이 논문은 Translatotron처럼 중간 이산 표현(text)를 통하지 않고, 입력 spectrum을 다른 spectrum으로 직접 매핑하는 end-to-end 음성 변환 모델이다. 인코더, 스펙트로그램 및 음소 디코더로 구성 되며, 보코더가 음성으로 변환하는 역할을 맡는다. 악센트, 프로소디 및 배경 소음에 관계없이 모든 입력 스피커의 음성을 고정 된 억양과 일관된 조음 및 단일 표준 대상 스피커의 음성으로 정규화하도록 학습하였고, 또한 청각 스피커(목소리에 장애가 있는)로부터의 음성을 표준화하도록 조정하였으며, 이는 성공하고, 이를 통한 비정형 목소리를 음성 인식기를 통한 WER measurement및 무작위 대상으로부터의 Mean Opinion Score (MOS) 측정을 통해 제안한 모델이 명료도 및 자연스러움이 얼만큼 개선되었는지 보여주고 있다. 마지막으로 화자 8명에 대하여, 1명과 나머지 7명 중 1개를 합성하고, 잡음(배경음)을 합성한 뒤 분리하는 것을 보여준다.
Model Architecture
먼저 이 모델의 목적은, "소스 음성을 입력으로 넣고, 대상 음성을 출력으로 생성/합성하는 end-to-end Seq2Seq model architecture"를 사용하여 타겟 신호를 직접 생성하며 처음부터 합성하는 end-to-end architecture이다. 즉, 화자 특성을 포함하여 모든 비언어적 정보를 투사하고 누가, 어디서, 어떻게 말하는지가 아니라 말하는 내용만 유지 하는 것이다. 이렇기 위해서는 텍스트로부터 indenpendent한, N:1 음성 변환 작업에 해당한다. 다르게 말하면 화자는 여러명이고 target 음성의 화자는 1명이라는 것이다. 사용되는 데이터는 쌍을 이루는 입력/출력 음성 발화의 병렬 모음이 필요하다.
Google에서는 Parallel WaveNet 기반 TTS 시스템을 이용하여 손으로 작성한 script로 부터 TTS를 합성하여 target set을 만들었다. TTS를 사용함으로서 다음을 보장 할 수 있다고 밝히는데, 1) 대상은 항상 일관된 스피커 및 악센트로 말하고, 2) 배경 소음이나 불쾌감이 없으며, 3)마지막으로, 필요한 만큼의 데이터셋을 합성할 수 있다.
Google은 2천 2백만 건의 영어 음성으로 구성된 30,000시간의 교육 세트에서 모델을 훈련시켰다고 한다. 이 모음을 사용하여 TTS 시스템을 통한 여성 음성으로 대상 발화를 생성했다고 한다. (엄청난 데이터 양...)
이제부터 모델 아키텍처에 대해 설명한다.
Parrtron model architecture
전체 모델 아키텍처는 이렇다. Encoder, Spectrogram decoder, ASR decoder가 사용되고 있다.
1) Encoder
Parrotron encoder part
빨간색 표시한 부분이 Encoder이다. Encoder에서 소개드릴 내용이 많다. 우선 이 모델에서 사용되는 핵심 아키텍처는 최근의 Attention 기반 end-to-end ASR 모델(1: Listen, Attend and Spell, 2: Spectral and Prosodic Transformations of Hearing-impaired Mandarin Speech)과 Tacotron(1: Tacotron2-Natural TTS synthesis by conditioning WaveNet on mel spectrogram predictions, 2: Tacotron-Towards end-to-end speech synthesis) 과 같은 TTS 모델을 기반으로 한다.
Parrotron의 기본 encoder 구성은 "Sequence-to-sequence models can directly translate foreign speech" 와 유사하며, 일부 변형이 되어있다. 위에 언급한 reference 논문에 대해 간단히 모델 부분만 체크하겠다. (https://arxiv.org/abs/1703.08581)
Sequence-to-sequence models can directly translate foreign speech
- Encoder는 8개의 layer로 이루어져있으며, Time X 80 X 3 tensor형태이다.
- 그 후, 2개의 CNN + ReLU 활성화를 통과한다. 여기에서 각 CNN은 32kernels로 이루어진 3 X 3 X에서 time X frequency이다. 이 CNN의 stride 는 2 X 2를 사용하였고, 결국 total factor는 4로 downsampling된다.
- 이후 Batch Normalization을 적용한다. CNN~Batch까지 다른 관점에서 바라보면 vgg랑 비슷하다고 볼 수 있지 않을까?
- 그 후, single bidrectional convolution LSTM (CLSTM)을 통과하는데, 이 때 filter 가 1 X 3 으로 통과한다.
- 마지막으로, 각 방향당 256크기의 LSTM을 갖는 BiLSTM을 통과하는데, 이 후 512차원의 Dense를 통과한다. Dense를 통해 Linear Projection을 하고 (512), Batch normalization과 ReLU가 함께 쓰인다.
- 즉 최종 Encoder의 ouptut은 512-dimensonal의 인코더 representation으로 나온다.
1-2> Decoder
- 64-dimensional의 word embedding된 y_{k-1}가 입력인데, 즉 text가 입력이다. 음성~ -> 인식 이므로 음성이 text로 바뀜. 심볼은 이전 time-step을 이용하며, 512-dimensional의 attention context vector를 사용한다.
- 128개의 Single hidden layer (attention)으로 이루어져있다.
- 이것들이 256-dimensional의 4개의 Unidirectional LSTM으로 통과한다.
- 마지막의 attention context와 LSTM output은 concatenation되어 출력 단어(vocabulary)를 예측하는 softmax로 통과한다.
1-3> Etc
- 9.8 parameter들을 가지고 있다. 생각보다 크지 않다.
- 전형적인 Seq2Seq으로, Teacher forcing을 사용하여 batch 당 64개의 utterances들을 구성하여 사용하였다.
- Adam optimizer를 사용하여 10개의 copy에서 비동기적 확률론적 경사하강(Stochastic gradient descent)를 사용하였다.
- 초기 lr은 1e-3이고, 백만 step 지나고 factor of 10을 decay한다.
- Beam search를 사용하였으며, Beam width는 3이며, 어떤 Language Model도 사용하지 않았다.
여기까지가 "Sequence-to-sequence models can directly translate foreign speech"의 Model Architecture와 Experimental Setup 부분을 정리한 내용이다.
다시 Parrotron으로 돌아가서,
16 kHz의 샘플링 된 waveform으로부터, 125-7600 Hz의 범위에서 80-channel log mel-spectrogram을 추출하였으며, 이 때, Hanning 윈도우를 사용하였고, 50ms 프레임 길이, 12.5ms 프레임을 겹쳤고, 1024-STFT 계수를 사용하여 추출하였다. (기존 위에 ref 삼은 논문보다 겹치는것을 줄였다.)
- 입력: 80channel log mel-spectrogram
- 2-layers CNN with 32 kernels (ReLU + BatchNormalization)
- Convolutional Bidirectional LSTM with 1x3 filter ==> 이를 통해 time step 마다 주파수 축을 통해서 뭉친다.
- 256-dimensional 3-layers LSTM
- 512 Dense + ReLU + Batchnormalization
- Get representation of Encoder input
위의 6줄이 Encoder의 구성이다.
2) Decoder (Spectrogram decoder)
Parrotron decoder part
최대한 쉽게 설명하기 위해 구분하여 진행해보자면,
- 디코더 타겟은 1025-dim STFT이며, 왜 이러냐면... NFFT를 1024으로 사용하고 hop을 25%사용했기 때문에 1025차원의 Spectrum을 얻는다. 마지막 1은 허수부분이다.
- Autoregressive RNN을 사용하여 decoder를 구성하였으며, 1번의 decoder step당 1 frame씩 인코딩 된 입력 sequence에서 출력 spectrogram으로 predict를 진행한다.
- previous(이전의) decoder time step으로부터의 예측은 256 ReLU가 연결된 2개의 layer를 포함하는 Pre-Net을 통과하는 것이 attention이 잘 먹힌다고 밝혔다. ***여기에서 Pre-Net은 이전에 review한 논문에 자세하게 나와 있음***
- LSTM 출력과 attention context vector을 concatenation하여 Linear transformation을 통해 target spectrogram을 예측한다.
- 마지막으로, ***마찬가지로 이전 논문에서의 Post-Net이 나옴*** 5-layers CNN Post-Net을 통과한다. 각각의 Post-Net은 5 x 1 형태의 512 filter를 갖고, BatchNormalization도 있으며, tanh activation 을 통해 출력 된다.
- 예측된 spectrogram에서 오디오 신호를 합성하기 위해 Griffin-Lim 알고리즘을 사용하여 예측된 magnitude와 일치하는 phase를 추정한 뒤 Inverse Short-Time Fourier Transform을 통해 waveform으로 변환한다.
- Griffin-Lim은 음질이 그닥 좋지 않으므로, Griffin-Lim보다 시간이 오래걸리지만 음성의 품질이 더 좋은 WaveRNN을 사용하여 사람들에게 평가하였다.
3) ASR 디코더를 이용한 Multitask Learning
Parrotron ASR decoder part
앞서 Translatotron에서의 구조와 비슷하다. 이 ASR decoder의 목적은 기본 언어의 높은 수준의 표현을 동시에 배우기 위해 인코더 네트워크에 multitask learning 기법을 사용하여 공동으로 train을 하면, encoder 의 음성의 feature를 더 잘 배운다고 한다. 쉽게 말해서, Signal-to-Signal로의 변환이 어렵기 때문에 중간에 ASR 디코더를 달아서 음성 부분을 학습시키는 것이다. 인코더 latent 표현에 따라 출력 음성의 (grapheme:자소 or phoneme:음소) transcript를 예측하는 역할을 맡는다. 이러한 multitask learning으로 train된 인코더는 기초적인 transcript에 대한 정보를 유지하는 입력의 latent 표현을 학습하는 것으로 생각할 수 있다.
ASR decoder의 input은 이전 step의 grapheme에 대한 64-dimensional 임베딩과(ASR decoder part) 512-dimensional의 attention context를 concatenate하여 생성된다. 그 후 256 unit LSTM layer로 전달 되고, 마지막으로 attention context와 LSTM의 output은 concatenated되어 softmax로 전달되고, 그 후 phoneme으로 출력 될 확률을 예측한다.
Application
1) 음성 정규화
이 실험은 임의의 speaker로 부터 사전 정의 된 target의 음성으로 변환된 음성을 정규화하는 목적이다. 임의의 speaker는, 크게 말해서 화자 별 특성에 따라 같은 script를 말해도 신호의 크기 및 세기, 잡음, 명료도가 다를 수 있다. Google은 input speaker가 누구든지 mapping된 target data로의 변환에 정규화하는 것을 목적으로 실험을 진행했다.
제안한 model의 output을 원래 입력 신호의 lingustic information을 보존하는지 평가하기 위해 음성 명료도를 측정하고(MOS), ASR 엔진을 사용하여 단어 오류율인 Word Error Rate (WER)를 평가했다. ASR 엔진은 WaveRNN으로 진행한 결과에 대해서만 평가했다.
보유한 음성의 ASR WER은 8.3%이라고 한다. 표에는 기입이 안되어 있다. 고품질 TTS 모델을 사용하여 ASR 엔진으로 평가하면 WER이 7.4%이라고 논문에 밝혀져있다.
위의 Table 1에서 맨 윗줄은 보조 ASR decoder가 없는 결과이다. 27.1%의 비교적 낮은 WER을 갖고 있다. 두번 째 줄인 Grapheme 단위로 예측하는 ASR decoder를 추가할 경우 19.9%로 약 7.3%가량 크게 개선되었다. Phoneme 단위로 ASR decoder를 달아도 맨 윗줄과는 확연한 차이가 보이는데, CLSTM 대신 decay(parameter 미세 조정)를 사용하며 LSTM을 2개 추가할 경우 가장 좋은 성능인 WER 17.6%을 달성하였다.
논문에서, CLSTM을 제거하여 매개 변수 수를 줄이면 성능이 크게 저하되며, 그러나 CLSTM 대신 2개의 additonal BLSTM을 사용하면 약간 향상 되는 동시에 모델이 단순화 된다고 한다. 이것이 마지막 줄의 결과이다.
위의 Table 2는 강력한 악센트와 배경 소음이 포함 된 보다 까다로운 테스트 셋에 대한 MOS 평가 와 ASR 성능의 평가 결과이다. 이 표에서 WER이 높은것이 중요한 것이 아니라, Real speech와 Parrotron의 결과에 대한 WER의 큰 차이가 없음으로 인해 언어적 내용을 보존하고 있음을 확인한다. 라고 주장하고있다.
정규화 실험 중 마지막으로, 모델이 동일한 TTS 음성으로 정규화 된 음성을 지속적으로 생성하는지에 대한 증명을 Table3을 통해 하였다. 8명의 영어 native들에게 발화된 model output 음성을 주고 평가하였는데, 질문 내용은
- 출력 음성에서 불일치가 포함되어 있는가? (Transcript와 다른지에 대한 평가인듯) ==> 0%
- 출력 언어는 일관된 조음, 표준 억양 및 prosody를 사용하는가? ==> 83.3%
위와 같고, 위와 같은 결과를 얻었다.
2) 청각 장애 연설의 정규화
위의 정규화 모델을 사용하여 standard 음성이 아닌, 청각 장애인을 유창한 음성으로 변환 할 수 있는지에 대한 실험이다. 이를 통해 사람들의 음성을 통한 의사 소통을 향상시키는 것으로 사용 될 수 있다고 주장한다.
실험은 러시아에서 태어난 10대에 청각장애를 소유한채로 영어를 배운 사람을 대상으로 진행된다.
요약하면, 표준어로부터 학습된 Parrotron 은 위의 청각 장애 언어르 완전히 정규화 하지 못하지만, 이를 해결 하기 위해 Google은 모든 매개 변수를 조정하고 모든 파라미터를 청각 장애 음성으로 적응(인코더만 미세 조정, 디코더와 음소 디코더 파라미터 모두 hold)시켰다. 그리하여 아래 표와 같은 결과를 얻었다.
첫째 줄의 Real speech는 청각 장애의 언어이며, MOS가 매우 낮고, 위에서 사용된 ASR 엔진의 WER은 89.2이다. 즉 워드 단위로 100개가 입력 될경우 10.8개 밖에 못맞춘 것이다.
두번째 줄의 Parrotron (male)은 위의 정규화 시스템을 그대로 사용했을 경우, MOS는 조금 나아지지만 마찬가지로 음성 인식 결과는 더 나빠졌다.
2)에서 제안한 fine tuning 기법(적응)으로 뽑은 결과는 MOS에서 1점 가량의 상승을 보였으며, WER도 일반인과 같은 성능을 내고 있다. 놀라운 결과라고 볼 수 있다.
위의 실험을 통해, 모든 fine tuning 전략이 음성을 이해하기 쉽고 훨씬 더 자연스러운 speech로 이어진다는 것을 밝혀냈다. 최고의 fine tuning은 모든 매개 변수를 조정하는 것이라고 논문에서 언급하고있다.
3) 음성 분리
이 실험은 Parrotron이 다양한 음성 응용에 사용될 수 있음을 설명하기 위해 만든 섹션이라고 한다. 중첩 된 혼합 음성 중 magnitude가 가장 큰 스피커의 신호를 재구성하는 음성 분리 작업이다. 최대 8개의 서로 다른 스피커의 즉각적인 혼합과 잡음(배경)을 넣어서 평가한다.
이 섹션은 SOTA separation 모델을 말하는 것이 아니다. 일반화 된 개방형 speaker set으로부터 speech를 생성할 수 있는지 평가하기 위해 분리를 진행한다고 한다. 솔직히 잘 이해가 안된다.
Google은 음성 신호의 즉각적인 혼합을 인위적으로 진행하기 위해, train set의 각 target 음성에 대해 1~7개의 발화를 무작위로 선택하여 배경 소음으로 혼합하였다. 백그라운드 발화 수도 임의로 선택된다. 혼합하기 전, 모든 발화를 비슷한 세기로 정규화한다.
배경에 대해 무작위로 샘플링 된 가중치 w(0.1~0.5)와 목표 발화에 대한 1-w로 두 신호를 평균화하여 target 발화와 배경 잡음을 혼합하였다. 이로 인해 인위적으로 구성된 모든 발화에서 12.15dB의 평균 SNR이 발생하고, 이에 대한 표준 편차는 4.7이라고 한다.
Parrotron이 분리 작업을 할 수 있는지 평가하기 위해 위의 정규화 파트 부분의 학습된 것을 가져와서 혼합 발화를 입력으로 넣고 모델을 훈련 시켜 해당하는 원래의 발화를 생성하는 식으로 진행하였다고 한다. 이를 ASR 엔진을 사용하여 분리 모델의 영향을 평가하였는데, 1) 배경 잡음을 넣기 전의 원래 깨끗한 발화, 2) 시끄러운 잡음인 배경 음과 음성을 혼합 한 후, 3) Parrotron을 실행하여 생성된 출력
형식으로 평가하였다고 한다.
위의 표를 보면, 잡음이 많은 세트인 "Noisy"에서의 WER은 33.2%이다. 이를 Parrotron을 사용하여(분리) denoising하면 17.3%의 WER를 얻었다고 한다. (음 근데 사실 이부분은 real time demonstration을 좀 보고 싶다.) 이를 통해 모델이 target speaker의 음성을 보존하고 다른 스피커로부터 분리 할 수 있음을 보여준다고 한다.
Conclusion
위 논문에선 이전 논문처럼 End-to-End 로 음성 변환을 진행하였는데, 필수적으로 script가 필요하지 않았다. 하지만 signal-to-signal 간의 음성 변환을 위하여 multitask learning 관점에서 음성 인식 디코더를 auxiliary part로 사용하였고, 이는 성능 개선에 도움이 되었다고 밝혔다. 위 논문의 목적은 "언어적 콘텐츠를 보존하고, 다른 스피커의 음성을 단일 대상 스피커의 음성으로 표준화하는 것" 이다. 청각 장애인의 음성이 model을 거쳐 단일 대상 스피커 (TTS)로 나올 경우, 제안 된 모델의 방법이 WER 개선에 영향을 미쳤다고 밝혔다. 또한 악센트가 많은 음성을 정규화를 통하여 표준 음성으로 변환하여 명료성을 향상시켰다. 추후 input 화자의 특성을 보존하며 정규화 및 개선하는 것을 목표로 두고 있다.
가장 큰 novelty는 N:1의 음성 변환을 정규화로 시키면서 좋은 성능을 내고 있다는 점, ASR 엔진을 이용한 명확한 평가를 하였다는 점, 그리고 청각 장애인 데이터셋으로부터 fine tuning을 통해 성능 개선을 했다는 점이라고 뽑고 싶다.
추가적으로, Google의 ASR엔진을 쉽게 사용할 수 있도록 API나 weight를 공유해주면 연구용으로 비교 및 사용하기 편할텐데... 아쉽다.
이번에 진행할 논문은 Translatotron: Direct speech-to-speech translation with a sequence-to-sequence model 이다. Google Research에서 published 하였으며, https://arxiv.org/abs/1904.06037 에서 확인해볼 수 있다.
(그림을 업로드하다가 중간에 렉이먹어서 도중에 쓴 것들이 다 날아갔다... 다시 씁니다ㅜ.ㅜ)
Intro, Related Work
한국인과 미국인이 서로 대화를 나누려 한다. 하지만 이 둘은 서로간의 언어 정보에 대해 하나도 모른다고 가정하겠다. 즉 한국인은 영어를 하나도 할 줄 모르고, 미국인도 마찬가지라고 가정한다.
한국인이 미국인에게 대화를 걸려면 1) 말을 하고, 2)이를 음성 인식하여, 3)인식 된 text를 번역하고, 4)얻은 text를 음성으로 합성해야 대화가 가능하다. 너무나 복잡하다. 사실 우리는 이 방법을 사용하여 외국인들과 대화를 하고 있지 않은가? 그만큼 우리는 대단한 존재일 수 있다.
어찌됐든, 위의 복잡한 단계를 해결할 중요한 이유가 하나 더 있다. 바로 중간에서 잘못 된 오류를 범할 경우, 마지막으로 음성 합성 된 결과값이 미국인에게 잘못 전달 될 수 있다. 예를 들어,
한국인: 제가 저기에 가려면 어떻게 해야하나요?
1) 음성 인식: 제가 저기에 가려면 어떻게 해야하나요?
2) 번역: How can I get there?
3) 음성 합성: ~~
4) 미국인에게 전달
이렇게 잘 전달되면 문제가 없다. 하지만 가령,
2) 번역: Can I go there?
라고 번역이 잘못 되었을 경우, 미국인은 yes라 할 것이고, 한국인은 pardon?을 외칠 것이다.
이러한 복잡한 문제를 해결한 연구 결과가 있다. 바로 지금 review할 논문인데, translatotron이다. 내가 생각한 이 논문의 novelty는 서로 다른 언어간의 음성 번역을 한 번에 진행 한 시발점(starting research) 이라고 생각한다.
딥러닝은 많은 발전이 이루어 졌고, 음성 인식, 번역, 음성 합성에서 굉장한 성능을 내고 있다. 하지만 위의 사례처럼 이용하려면 음성 인식 -> 번역 -> 합성이 이루어져야 한다. 하지만 이 논문은 이것을 한 번에 다 해내고 있다. 심지어 목소리까지 바꿀 수 있다.
이 논문의 실험은 스페인어-영어 데이터셋으로 진행하였다.
자 그럼 이 논문에 대해 알아 가 봅시다.
Method
모델 구조는 별도로 훈련 된 여러 구성 요소로 구성된다. 즉 이 모델은 end-to-end가 아니고, pretrain된 것들도 사용한다.
전체 모델 아키텍처는 아래 그림과 같다.
- Primary task: target spectrogram을 생성하는 attention based Seq2Seq
- Speaker Encoder: 이 부분은 선택적으로 쓰이는 부분인데, 대상의 목소리를 원할 경우 바꿔서 번역할 수 있음
- Vocoder: target spectrogram을 시간도메인인 waveform형태로(음성) 바꾸는 부분
- Auxiliary tasks: source와 target의 phoneme sequence 예측 하는 부분
차례차례 보도록 해봅시다.
- Primary task, Encoder
먼저 Translatotron의 Encoder부분은 아래 빨간 표시한 곳이다.
Translatotron Encoder Part(빨간 표시)
Encoder의 input은 80channel log-mel-spectrogram이 사용된다. 여기에서 80channel은 mel을 80 dimension으로 뽑았단 얘기이다. librosa의 n_mels와 같다. 그렇게 뽑은 mel-spectrogram에 log값을 취해준 것이다.
그 다음 8-layer Stacked Bidrectional LSTM을 사용한 것으로 나와있다. BLSTM을 8개 쌓은것이다. 이 최종 output은 speaker encoder를 사용했을 경우 i-vector와 concat하여 decoder ouptut과 transformer 에서 사용되는 multi-head attention을 통해 encoder-decoder간 scaled-dot product attention이 이루어진다. speaker encoder가 사용되지 않았을 경우엔 저 concat 부분은 사용되지 않는다. 중간에 Auxiliary recogniton tasks로 가는 화살표가 있는데 이것은 마지막에 설명할 예정
- Primary task, Decoder
Translatotron Decoder Part(빨간 표시)
Spectrogram Decoder는 Text-to-Speech에서 좋은 평가를 받고 있는, 마찬가지로 구글에서 published 한 Tacotron2 구조와 유사하다. Pre-net, Autoregressive LSTM, Post-net 을 포함하고 있다. 여기에서,
Pre-net: 2-layer FC
Autoregressive LSTM: Bi-directiona LSTM(Tacotron2 encoder), LSTM(2-Uni-directional layers in Tacotron2 decoder)
Post-net: 5-layer CNN with residual connections 으로서, mel scaled filter bank spectrogram을 개선하는 역할
로 정의할 수 있다.
Tacotron2 model architecture
Tacotron2의 Encoder는 text를 character 단위의 embedding을 하고, Pre-net을 거친다. Pre-net은 정확히,
Pre-net: (Dense -> ReLu -> Dropout) X 2
로 이루어져 있다. 그 후, CBHG를 통과하는데,
CBHG: Conv1D Bank -> Max pooling -> Conv1D projection -> Conv1D layer, Conv1D layer + First input(이 부분이 residual connections) -> Highway Network(4 layers of Dense - ReLu) -> Bidirectional RNN
으로 이루어져 있다. Encoder의 최종 결과는 embedding result가 나온다. 위의 모든 process를 mel-spectrogram과 최적의 alignment를 하기 위해서라고 생각하면 좋을 것 같다. 너무 복잡하지만..
Tacotron2의 Decoder는 Encoder와 거의 비슷한데, RNN의 구조를 띄고 있다. 즉 각 step마다 output (1개의 spectrogram frame)을 출력한다. 그리고 autoregressive 한 형태이므로, 이전 step을 사용하여 현재 step의 frame을 예측한다. 매 step마다 encoder의 context vector와 attention을 통해 output 1개를 얻는 것이다. 최종적으로 projection 하는 decoder의 hidden layer의 output은 2개의 256으로 이루어진 FC가 를 가장 먼저 통과한다. 즉 Dense 형태로, (256, 1)의 형태를 얻는다.
그 후 LSTM과 이루어진 context vector는 80개의 neurons을 갖는 FC로 통과한다. 이게 바로 mel-spectrogram의 channel인 n_mel와 동일하다! 이 최종 부분이 spectrogram을 frame by frame으로 예측한다. 그 후 PreNet으로 다시 들어가고, linear scale spectrogram을 얻는다. 아마 Reduction Factor 를 3으로 사용했던 것 같은데, 그렇다면 3개의 predicted spectrogram을 사용하여 1개의 linear scale spectrogram을 얻는다.
attended ecoder outputs
Attention 부분에 대해 조금 더 언급하고 싶어서 수식을 캡쳐했다. context vector Ci 는 encoder의 output(h)와 attention weights(alpha)의 product로 연산되는데, alpha_ij는 아래의 식에 의해 연산된다.
Attention weights
자 많이 보던거 나왔죠? exp/exp합은 softmax이다. 대충 눈 도장 익히면 아~확률 구하는구나 라고 생각하면 편하다.
e_ij = vaT tanh(Wsi-1 + Vhj + Ufi,j + b) 인데,
si-1: decoder LSTM의 이전 hidden state
alpha_i-1 : 이전 attention weight
hj: j번째 encoder hidden state
W, V, U, va 그리고 b: 학습시 사용된 parameter들
fi, j: 공식에 의한 계산된 위치
fi: F * alpha_i -1
F: CNN 연산
이다.. 복잡한데, 제 설명이 부족하시다 생각하신 분께서는 Tacotron2 와 attentive-attention mechanism을 읽어보시는 것을 추천드립니다.
정리하면, Tacotron2는 encoder에서 text를 입력받아 Pre-net, CBHG를 통해 character embedding result를 얻고, decoder에서는 80channel의 log-mel-spectrogram 입력을 받아 encoder-decoder attention을 통해, 256 dense로 1개를 예측하고, 다시 그 값이 80 dense를 통해 80channel의 spectrogram이 통과한다. 이 때, frame by frame, autoregressive방식으로 진행되고, 위의 output은 Post-Net을 통과하여 linear scale spectrogram으로 얻는다. 이게 다 ~~끝나고 vocoder를 통해 음성이 복원된다.
Translatotron도 유사하다. 이 떄, 4 or 6 LSTM이 성능이 좋다고 언급되어있다.
Translatotron의 decoder에서의 예측은 1025dimension의 log spectrogram의 frame을 예측한다. 각 디코딩 단계마다 2개의 스펙트로그램 frame을 예측한다. 이렇게 사용하는 이유는 음성 신호가 연속성을 띄고 있기 때문이고, decoder의 부하를 줄여주기 때문이다.
쓰고 보니 Tacotron2 리뷰를 따로 안해도 될듯 ㅎㅎ
- Vocoder
아래 부분의 빨간색 표시가 Vocoder 부분이다.
Griffin-Lim을 기본적으로 사용하였다. 하지만 MOS테스트에서 음성의 자연성을 평가할 때 WaveRNN을 사용하였다. Griffin-Lim은 CPU로 돌릴 수 있지만, WaveRNN은 시간이 더 오래걸리고, GPU 기반이다. 그러나 음성 복원 품질은 WaveRNN이 더 좋기때문에 이를 이용하여 테스트한 듯.
또한 Vocoder에서 reduction factor를 사용하여 감소 계수 2로 frame을 계수만큼 예측한다. 이 계수만큼의 log-spectrogram을 생성한다. 이렇게 복원된 음성을 직접 들을 수 있다.
- Speaker Encoder
이 부분에서는, D-벡터를 뽑아서 사용한다. D-벡터는 Speaker Independent System의 특징인데, 화자별 차이의 벡터값 정도로 생각하면 될 것 같다. Speaker vefirication를 위한 pretrained 된 것을 여기에서 사용한다.
위 논문에서, 851k 스피커, 8개 언어에 대한 정보를 사용했다고 밝혔다. training 시에는 사용하지 않았고, inference에 합성할때에만 썼다고 한다. 256차원으로 값이 나오면, 이를 linear projection을 통해 16으로 줄이고, 마지막 encoder BLSTM layer의 output과 concat했다고 밝혔다. 오직 tanfer task에만 사용되었다.
- Auxiliary recognition tasks
각각 attention이 구성되어 있는 소스 및 대상 음소 시퀀스를 예측하는 파트이다. BLSTM의 마지막 값이 여기에 연결된다. single head attention이 있는 2 layer LSTM으로 구성되어 있다. 여기에서, 한 입력은 소스 음소 (스페인어) 이고 다른 입력은 대상 (영어) 이다. signal-to-signal의 변환이 모델에서 버거워 하기 때문에, multitask learning 기법을 사용하여 음성을 phoneme 단위로 인식하여, 이 정보를 decoder 단에 전해주어 음성 변환을 도운 task라고 보면 되겠다. 3개의 loss가 사용되었다. 이 task를 통해 BLEU score가 개선되었다고 밝히고 있다.
- training하는 동안 speech transcripts를 사용하는것이 중요하다고 함
아마도 signal-to-signal간의 학습이 잘 안되었기 때문이지 않았을까 싶다.
내 느낌점은, 처음 이 논문이 나오고, demonstration을 들어보고나서 정말 놀라웠었다. 작년 5월에 처음 봤는데 나는 무슨 연구를 하고 있는 건가 싶었다. 새로운 길을 개척한 논문이라고 평가하고 싶다. 벌써 8개월 정도가 지났는데 어떤 성능을 갖는 end-to-end 가 나올지 기대된다.
이번에 Review할 논문은 "Voice Impersonation using Generative Adversarial Networks" 이다. Carnegie Mellon University의 "Yang Gao" et al. 이 작성하였으며, 2018.02.19에 Arxiv에 출간되었고, ICASSP 2018에 실렸다. 해당 논문은 https://arxiv.org/abs/1802.06840 에서 볼 수 있다.
1. Overview
해당 논문은, 음성 변환, 변조, 흉내 (Voice Conversion, Impersonation)을 다루는 내용이다. Voice Impersonation에서 결과 음성은 target 스피커에서 자연스럽게 생성된 느낌을 확실하게 전달해야하며, 피치 및 기타 인식 가능한 신호 품질뿐만 아니라 target 스피커의 style을 모방해야한다. 이 논문에서는 Impersonation된 음성 합성을 위한 신경망 기반의 음성 품질 및 스타일 모방 프레임 워크인 VoiceGAN을 제안하며, 이 프레임워크는 GAN을 기반으로 한다.
모델의 입력은 Spectrogram을 받고 있고, 제안한 VoiceGAN 네트워크의 output은 Griffin-Lim 방법을 사용하여 time 도메인 신호를 재구성하여 합성된 Spectrogram을 내보낸다. 논문에서 주장하는 Voice style transfer에 대한 내용은, 실제로 성별을 바꿔가며 pair-dataset 기반으로 결과를 보여주고 있다.
한 사람이 다른 사람의 목소리를 모방하여 다른 사람과 같은 소리를 내려고 시도하는 음성 가장(Voice Impersonation)은 복잡한 현상이다. Impersonation 한 사람은(X) Impersonation 한 사람의 목소리(x)에서 가장 두드러진 측면을 직관적으로 일치시켜 변환을 수행한다. 이 프로세스에서 Impersonation을 통해 변경한 음성의 가장 일반적인 특성이 음성 품질 요소와 스타일 요소이다.
하지만 음성은 설명하기 어려운 개체이다. Nasality(콧소리), 거칠기, 숨가쁨 등과 같은 일부 측면이 기존 연구를 통해 확인되었지만, 이들 중 대부분은 화자간에 의미 있는 비교를 허용하는 방식으로 정량화 하기가 힘들다. target 화자의 말하기 속도 등의 특징들을 시간적 피치 및 에너지 패턴(magnitude)을 포함하는 스타일 요소는 정확한 정의와 비교 가능성 측면에서 유사하게 모호하다.
(개인 생각: 그래서 우리는 MOS를 측정하거나, 합성된 음질의 SNR(Signal-to-Noise Ratio)등을 통해 비교를 하기도 한다. 하지만 가장 직관적인 것은 실제로 사람이 들어보는 것이다.)
이 논문에서는, 다른 컨텐츠를 수정하지 않고 음성의 특정 측면만 변환하는 것이 목표이다. 이상적으로 스타일 특징을 결정하는 음성의 측면을 식별, 격리 및 명시적으로 측정한 뒤 이를 사용하여 대상 음성을 수정하기도 하지만, 이러한 특징들은 주관적/객관적으로 식별이 가능하지만 위에 언급한 것 처럼 정량화 할 수 없기 때문에 일반적으로 어렵다고 주장한다.
저자의 목표는 식별할 수 있는 스타일의 측면을 전달하는 매커니즘을 개발하는 것이다. 이러한 맥락에서 가장 관련성이 높은 선행 연구는 소스 음성을 대상 음성으로 변환하는 특정 문제를 다루는 음성 변환과 관련이 있다. 일반적으로 음성 변환은 Pitch 및 Spectrul Envelope과 같은 신호의 순간 특성을 수정한다. 여기에 codebook based conversion (Voice Conversion through Vector Quantization)과 minimum-mean-squared error linear estimator (Voice Conversion Based on Maximum-Likelihood Estimation of Spectral Parameter Trajectory), Neural Networks (Voice conversion using deep neural networks with layerwise generative training) 등 여러 기법들을 사용한다. 위 방법들은 모두 신호의 순간적인 특성 변화에 매우 효과적이며, 심지어 일부 운율 신호를 mapping 할 수 있지만, 일반적으로 linguistic한 의미를 측정할 수 없다.
또한 음성 변환을 효과적으로 하기 위해서 train/test set간의 녹음이 완벽하게 시간이 정렬되어 있어야 한다. 이는 일반적으로 녹음을 서로 맞추기 위해 녹음 시간을 왜곡하여 충족시키는 요구 사항인데, 이렇게 녹음하기에는 비현실적이다. 또한 목적이 음성의 도메인 변환을 수행하는 것이 아니라 스타일을 변형시키는 것만 배울 경우, 위의 정렬은 부적절 할 수 있다.
이러한 맥락에서 저자는 GAN을 주장한다. Discriminator는 병렬 신호들 사이의 mapping을 배우기보다는 원하는 스타일 특징을 가진 데이터와 그렇지 않은 데이터를 구별한다. Generator는 Discriminator를 어리석게 만드는 방법을 배워야한다. D와 G 모두 Deep Learning에 의해 모델링되며, 적절한 설계와 충분한 훈련 데이터로 변환을 모델링 할 수 있다. 기의 음성 변환 방법에 필요한 것과 같은 병렬 데이터는 필요하지 않다. (하지만... 결과를 들어보면 pair dataset에 대한 결과만 나오며, 뒤에서 소개될 Loss에는 supervised로서, label이 주어져 있음)
음성 신호 변환에 GAN을 사용하기에는 여러 문제가 있다. GAN에서 널리 사용되는 이미지와는 달리 음성은 크기가 고정되어 있지 않으며(즉, 지속 시간이 고정되어 있지 않음), 축소 될 때 스타일 특성이 많이 손실된다. 음성과 같은 sequencial 데이터 생성은 이미지와 비교하여 더 어려운 문제이다. 프로세스를 순진하게 구현하면 언어, 스타일 또는 이해하기 어려운 내용을 잃은 데이터가 생성 될 수 있다.(매우 공감...) 이 연구에서는 음성 변환 문제에 대한 여러 GAN 모델을 소개하고, 저자의 모델과 해당 학습 알고리즘은 언어 고유의 특정 문제를 고려하도록 설계되었다. 구체적으로, 저자는 모델 구조와 학습 알고리즘을 적절히 선택하고 GAN 프레임워크에 적절한 Discriminator를 도입하여 다른 측면을 모방하기 위해 다른 언어를 수정하거나 Linguistic 정보를 잃지 않고 음성의 특정 특성 유지 방법을 소개한다.
3. Related Works
3-1. GAN
Fig. 1. The original GAN model
Original GAN 모델은 generator G(z)와 Discriminator D(x)로 이루어져 있다.
Generator G는 일부 표준 확률 분포 함수 Pz 로부터 도출 된 랜덤 변수 z 를 입력으로 취하며, 표준 정규 분포를 따르는 출력 벡터 xz 를 생성한다.
Discriminator D는 Px에서 추출한 표본 xPx, 즉 모델링하려는 실제 분포와 Generator G에서 생성한 표본을 구별한다. T는 벡터 x가 PX으로부터 도출된 사건이라고 가정하면, Px에서 Discriminator는 T의 사후 확률, 즉 D(x)=P(T|X)를 계산한다.
GAN의 수식은 아래와 같다.
GANGAN Discriminator LossGAN Generator Loss
부가적으로 설명을 달아보겠다.
Discriminator의 역할인 maxDV(D) 는 실제 이미지들을 더 잘 인식하는 것이 목적이고,
Generator의 역할인 minGV(G) 는 가짜 이미지들이 Discriminator를 속이는 것이 목적이다.
여기에서,
ExPx 는 x 가 real data로부터 도출된 sample data
EzPZ 는 z 가 fake data(noise)로 부터 도출된 sample data
D(x) 는 실제 이미지가 들어갔을 때의 D(real)의 확률
1−D(xz) 는 가짜 이미지가 들어갔을 때의 D(fake)의 확률
[logD(x)] 는 D(real)의 likelihood
[log(1−D(xz))] 는 D(fake)의 likelihood
이다.
더 좋은 품질의 GAN output을 얻기 위해서는
Generator:D(xz) 를 minimize 시켜야 하고,
Discriminator:D(x) 를 maximize 시켜야 한다.
즉 결론적으로 G 와 D는 적대적(Adversarial)이다. 우리는 종종 GAN을 미니 맥스 게임으로 정의하는데, G는 V를 최소화하고 D는 V를 최대화하기를 원하기 때문이다.
3-2. Style transfer GAN
Fig. 2. Style transfer by GAN
2번째로 논문에서 소개하는 것은 Style transfer를 GAN을 통해서 한다는 것이다. PA분포로부터 가져온 input data xA 를 Generator를 통해 transformed 하여 xAB를 만든다. 이것을 Transformer GAB 라고 부른다. (Attention is all you need논문에 소개된 Transformer 아닙니다..) GAB의 목적은 xA를 분포 PB에서 기본적으로 발생하는 변수 xB의 스타일로 변환하는 것이다.
Discriminator DB는 xB에서 PB의 실제 드로우와 PA에서 xA의 드로우를 변환하여 얻은 인스턴스 xAB 중 누가 진짜인지를 구별하는 역할을 한다. Style transfer 최적화는 아래의 공식과 같다.
Style transfer Generator Loss and Discriminator Loss
generator G는 generator loss인 LG을 최소화하여 업데이트가 되는 반면, discriminator D는 discriminator loss인 LD를 최소화하여 업데이트한다.
3-3. DiscoGAN
Fig. 3. The DiscoGAN model
DiscoGAN은 카테고리 두 가지 범주의 데이터인 A 및 B를 서로 변환하려고 시도하는 대칭 모델이다. DiscoGAN은 2개의 Generator를 포함하고 있는데,
- GAB = A의 분포 PA로부터 얻은 xA를 B로 변환 ==> xAB ==> GAB(xA)
- GBA = B의 분포 PB로부터 얻은 xB를 A로 변환 ==> xBA ==> GBA(xB)
두 Generator는 서로 역의 관계를 갖고 있다.
GAB의 목표는 B의 style을 모방한 GAB(xAB)의 output이 B 데이터 분포인 PB와 구별되지 않도록 하는 것이다. GBA 도 역의 관계로 생각하면 될 것이다.
다음은 DiscoGAN의 loss 부분이다.
DiscoGAN loss 부분 설명
빨간색 그림은 내가 표시한 것이다.
위에서 언급한 GAN loss와 Style transfer loss를 확실히 이해하였다면 이 부분도 어렵지 않게 이해할 수 있다.
2개의 Generator Loss
LGA는 given data B를 A로 변환한 뒤의 real일 확률의 negative likelihood 값이며,
LGB는 given data A를 B로 변환한 뒤의 real일 확률의 negative likelihood 값이다.
즉 둘다 작을수록 좋다.
또한 그림에 보이는 Reconstruction Loss가 2개가 있다. DiscoGAN에서는 d를 두 이미지의 거리로 계산하였으며, 이때 MSEloss를 사용하였다.
LCONSTA=d(GBA(GAB(xA)),xA)
Reconstruction A loss는 xA와 B로 변환하였다가 다시 A로 변환한 이미지와의 MSEloss 값이며,
LCONSTB=d(GAB(GBA(xB)),xB)
Reconstruction B loss는 xB와 A로 변환하였다가 다시 B로 변환한 이미지와의 MSEloss 값이다.
DiscoGAN GAN Loss
이제 전체 loss를 정리해보겠다.
2개의 Generator loss는 다음과 같이 정의된다
LGANAB=LGB+LCONSTA
LGANBA=LGA+LCONSTB
그러므로,
LG=LGAB+LGBA
==>LGB+LCONSTA+LGA+LCONSTB
2개의 Discriminator loss들은 다음과 같이 정의된다.
LDA=−ExAPA[logDA(xA)]−ExBPB[log(1−DA(GBA(xB)))]
LDB=−ExBPB[logDB(xB)]−ExAPA[log(1−DB(GAB(xA)))]
따라서 전체 LD 는
LD=−ExAPA[logDA(xA)]−ExBPB[log(1−DA(GBA(xB)))]−ExBPB[logDB(xB)]−ExAPA[log(1−DB(GAB(xA)))] 가 된다.
4. Proposed Model: VoiceGAN
DiscoGAN은 원래 이미지의 스타일을 변형할 수 있도록 설계되었다. 저자는 이 모델을 음성에 적용하기위해 음성을 Spectrogram으로 변환하여 진행하였다. (단순히 STFT한 Spectrogram인지, Mel-Spectrogram인지 정확히 논문에 언급은 안되었지만, Mel-Spectrogram으로 변환한 뒤 Linear Prediction을 한 후 Griffin-Lim Method를 적용한 것 처럼 보임)
위에 언급한 것처럼, 보통의 GAN은 이미지에서 많이 사용되고 있고, 음성은 적용하기가 어려운 문제점을 저자는 아래와 같이 주장한다.
1. Original DiscoGAN은 고정 크기의 이미지에서 작동하도록 설계되었다. 본질적으로 가변 크기의 음성 신호와 함께 작동하려면 새로운 디자인에서 이 제약 조건을 완화해야한다.
2. 음성 신호의 언어 정보가 손실되지 않도록 하는 것이 중요하다.
3. 저자의 목표는 연설의 특정 측면을 수정하는 것이다. 예를 들어 스타일을 구현하기 위해 모델에 추가 구성 요소를 추가한다.
저자는 위의 문제점을 개선할 VoiceGAN을 제안한다. 그럼 이제 VoiceGAN에 대하여 알아볼 시간이다.
Voice GAN의 Generator와 Discriminator
모델 아키텍쳐는 위와 같은데, DiscoGAN의 Generator와 VoiceGAN의 Generator 부분은 같다. 차별점은, Discriminator인데,
1. Adaptive Pooling layer는 CNN layer 이후 및 MLP 계층 이전에 추가된다.
2. 채널 별 풀링이 포함 된다.
3. 가변 크기의 feature map을 고정 된 차원의 벡터로 변환한다.
아쉽지만 여기에서 Hyperparameter에 대한 언급은 생략되어 있다. 코드라도 공개 했으면 좋았을텐데..
우선 VoiceGAN의 reconstruction loss를 보면 아래와 같다.
LCONSTA=αd(XABA,xA)+βd(xAB,xA)
LCONSTB=αd(XBAB,xB)+βd(xBA,xB)
식의 뒷 편을 자세히 보면
βd(xAB,xA) 와 βd(xBA,xB) 가 추가 되었다. 추가한 이유를 저자는 "For retain the linguistic information" 라고 소개하고 있다.
d(xAB,xA) 는 xA로 변환 된 후에도 xA의 언어적 정보를 유지하려고 시도한다고 설명하고 있다.
αβ에 대해서는, 변환 후 언어 정보의 정확한 변환 및 보존을 하기 위한 매개변수라고 설명하고 있다. 하지만, 아쉬운 점으로는 가장 중요한 hyperparameter에 대해서 정확한 값에 대해 공개를 하지 않았다.ㅜㅜ 예측하건데 굉장히 작은 값으로 multiple 한 것이 아닐까 싶다. 논문에서는 "Careful choice of α,β ensures both" 라고만 공개하고 있다.
저자는 TIDIGITS dataset을 사용하였다. TIDIGITS dataset은 326의 speaker들이 있으며(111 men, 114 women, 50 boys, 51 girls) 각 각의 speaker들은 77개의 문장을 녹음하였다. Sampling rate는 16kHz이고, 논문에서 주장하는 Style transfer는 Gender 로 설정하였다.
사용된 문장은 숫자를 읽는 문장이다. 아랫쪽에 나오겠지만, 5 4 3 2 1 과 같은 음성을 사용하였다. 다르게 말하면, 연속적 대화보다는 쉬운 task로 볼 수 있고, 고립 단어 변환으로 볼 수도 있을 것 같다.
위의 그림은 음성 변환 그림이다. 맨 왼쪽 위가 남자 xA이고, 위쪽 가운데가 변환한 여자 xAB, 위쪽 오른쪽이 다시 원래 남자로 변환한 xABA이다.
몇 가지 음성에 대한 결과를 랜덤으로 뽑아서 저자가 github에 공개를 해놓았다. 여기서 들어볼 수 있다.
6. Conclusion
개인적인 생각으로는, 기존에 음성 변환 및 생성에 있어서 GAN이 잘 작동하지 않았던 연구사례들이 많다. 이 부분을 저자는 언어학적 정보를 잃지 않기 위해 Style Embedding Discriminator를 추가하였다. 간단한 아이디어지만 이 부분은 Novel하다 볼 수 있으며, 더 발전시킬 수 있을 것 같다.
아쉬운 점으로는
1. 코드 공개가 없다는 점
2. Hyperparameter 언급이 없다는 점
3. 결과가 paired lingustic만 나온다는 점
으로 꼽아볼 수 있다.
- 주관적인 생각이 들어있으므로 관련 논문에 대해 잘못된 부분이나 comment는 언제나 환영합니다.
이 논문은 LAS(Listen, Attend and Spell) model을 소개하고 있다. LAS는 기존의 DNN-HMM모델과는 다른 스피치 발화를 문자로 변경해주는 뉴럴넷이다. 기존의 DNN-HMM모델과 다르다고 주장하는 이유는, 모든 것을 End-to-End로 학습하기 때문이라고 한다. 시스템은 크게 2개의 구성요소로 되어있는데 1개는 Encoder Part의 Listener, 1개는 Decoder Part의 Speller이다. Listener는 피라미드 모양의 RNN을 사용하고 있으며, 이 때 input 데이터로는 filter bank를 통과한 Spectrum들을 사용하고 있다. Speller는 Attention-Based RNN이며 Listener의 output을 input으로 받아 글자로 내뱉어주는 역할을 한다.
논문은 2015년 8월에 쓰여졌고, 이때 당시 state-of-the-art 였던 CLDNN-HMM 모델의 WER은 8.0% 였지만, 이 논문에서 제안하는 WER은 14.1%였다. 이 때, 14.1%는 사전이나 언어 모델 없이 학습하였을 때의 결과이고, 언어 모델을 사용할 때의 WER은 10.3%라고 한다.
2. Introduction
(논문이 쓰여진 2015년 8월 즈음) State-of-the-art 음성인식 모델은 음향 모델(Acoustic Model), 언어 모델(Language Model), 명사 모델(Pronunciation), 언어 정규화(Text normalization) 등 다양한 구성 요소로 이루어진 복잡한 시스템이었다. 예를 들어 n-gram 언어 모델과 Hidden Markov Models (HMMs)은 문장 내의 단어/기호간 strong한 Markovian independence 추정을 만든다. CTC (Connectionist Temporal Classification)와 DNN-HMM 시스템은 뉴럴 네트워크가 독립된 예측을 다른 시간에서 하게끔 하고, HMM이나 언어 모델은 시간 경과에 따라 이러한 예측 간의 종속성을 도입하게 해준다.
이렇듯, 2개 이상의 구성 요소를 합쳐서 음성 인식 시스템을 만들었지만, 이 논문에서 제안하는 바로는 End-to-End로 음성을 문자로 변경하는 시도를 보인다. 즉, input으로 음성을 받아서 언어 모델이나 명사 모델, Hmm 등을 쓰지 않고 output으로 character로 내보내는 것을 말한다. 이 방법은 Seq2Seq 학습 framework에 에 Attention 기법을 도입하는 것을 참고로 한다. Encoder로 Listener라는 이름을 갖는 RNN을 사용하고, decoder로 Speller라는 이름을 갖는 RNN을 사용한다.
3. Model and Methods
x = (x1, x2, ...., xt) 를 필터 뱅크를 통과한 스펙트럼 특징들인 입력 시퀀스로 두고, y = (<sos>, y1, ...., ys, <eos>)문자의 출력 순서라고 가정하자. 이 때, yi는 {a, ...., z, 0, ...., 9, <space>, <comma>, <period>, <apostrophe>, <unk>) 를 포함하는데, sos는 sentence의 시작 토큰이고, eos는 sentence의 종료 토큰이다.(start-of-sentence: sos, end-of-sentence: eos) 또한 <unk>는 악센트 문자와 같이 unknown token으로 가정하고 있으며, <space>, <comma>, <apostrophe> 같은 경우는 스페이스, 콤마, ' 와 같은 문자이다. 즉 알파벳 a~z, 숫자 0~9, 그리고 위에서 언급한 것들이 모두 y에 포함된다는 것이다.
LAS 모델은 각각의 출력 문자 yi를 이전 문자 y<i에 대한 조건부 분포로 모델링하고, 확률에 대한 Chain Rule을 사용하여 입력 신호 x를 y로 모델링 한다. 이때의 공식은 다음과 같다.
즉 주어진 음성 x에 대하여 출력문자 y가 될 확률은, 전체 문자 y < i(위에서의 a~z, 0~9, 등)에 대한 x의 조건부 분포(Conditional Distribution)로 모델링한다고 볼 수 있다. 위의 식은 음향 신호가 입력으로 들어오면, 문자 시퀀스의 조건부 확률을 직접 예측할 수 있기 때문에 모델을 차별화 된 End-to-End로 만들어 준다.
아래의 그림은 Paper에 개재된 그림으로 LAS 모델의 구조인 Listener(Encoder)와 Speller(Decoder)를 설명해주고 있다.
1) 먼저 Listener는 Encoder로서 음성 신호를 high level feature들로 변환하는 역할을 LAS내에서 맡고 있다. Listener는 BLSTM을 Pyramidal 형식으로 3개를 붙여서 사용하고 있다. 논문에서는 이를 pBLSTM으로 부르고 있으며, pyramidal 하게 사용하는 이유는 pBLSTM 1개당 연산속도를 2배로 줄여주기 때문이다.
h를 Listen Encoder라 하고, i를 i-th time step이라하고, j를 from the j-th layer라 하였을 때,
3개의 BLSTM의 top of the bottom에 쌓은 pBLSTM은 time resolution을 2의 3승만큼, 즉 8 배만큼 줄여준다고 한다.
2) Speller는 Decoder로서, attention-based LSTM 변환기 역할을 맡고 있다. 즉, 모든 출력 단계에서 변환기는 이전에 본 모든 문자를 조건으로 한 다음 문자에 대한 확률 분포를 생성한다. yi에 대한 분포는 디코더 상태 si 및 컨텍스트 ci의 함수이다. 디코더 상태 si는 이전 상태 si-1, 이전에 출력 된 문자 yi-1 및 컨텍스트 ci-1의 함수이다. 컨텍스트 벡터 ci는 attention-mechanism에 의해 생성된다.
여기서 CharacterDistribution은 charcter 위로 softmax 출력이있는 MLP이고 RNN은 2계층 LSTM이다.
매 time step마다, attention mechanism인 AttentionContext ci는 컨텍스트 벡터를 생성하고, 다음 문자를 생성하는데 필요한 음향 신호의 정보를 캡슐화한다. attention 모델은 내용 기반이며, 디코더 상태 si의 내용은 attention 벡터 ai를 생성하기 위해 h의 time step u를 나타내는 hu의 내용과 일치한다. 벡터 hu는 ai를 사용하여 linear하게 블렌딩되어 AttentionContext를 생성한다.
3) 이 모델의 학습은, 입력 음성에 대해 알맞는 sequence의 log probability를 maximize한다. 공식은 아래와 같다.
4) 디코딩 관련하여, test 시에 가장 근접한 character sequence를 주어진 음향에 대해 찾는다. 공식은 아래와 같다.
4. Experiments and results
저자는 3백만개의 Google Voice Search utterances(2000시간의 데이터셋)를 이용했다. 거의 10시간의 발화들이 랜덤으로 선택되어 validation set으로 사용되었다. room simulator를 이용하여 Data Augmentation를 진행하였고, 이 때 기존 녹음된 것과 같은 reverberation과 noise를 추가했다.
음성 데이터 input은 Mel-Spectrogram을 사용하여 number of mel을 40으로 주고 10ms마다 features들을 뽑았다 (40 dimensional log-mel filter bank).
Text Normalization은 모든 캐릭터들을 lower case English alphanumerics로 일반화 해주었다. 알파벳, 숫자, space, comma, period, apostrophe는 그대로 유지해주고 나머지들을 <unk> token으로 치환해주었다. 또한 맨 앞쪽에 언급한 것처럼, 모든 발화의 앞쪽에는 <sos>를, 끝쪽에는 <eos>를 패딩해주었다.
논문이 쓰여진 당시의 State-of-the-art의 CLDNN-HMM의 Clean WER는 8.0이고, Noisy WER는 8.9였다. 논문 실험 결과인 LAS는 그보다 미치진 못하였다.
저자는 Listen Function에서(Encoder part) 3개의 pBLSTM을 쓰기 때문에 시간을 2^3= 8times 만큼 줄여준다고 주장하고 있다. weights들은 uniform distribution (-0.1, 0.1)로 초기화 하였다. Gradient는 Asynchronous Stochastic Gradient Descent (ASGD)를 train 하는데에 사용했다. learning rate는 0.2로 시작하여 20 에폭마다 0.98씩 decay를 하였다. 모델 학습하는 데에 거의 2주간의 시간이 걸렸다고 한다. 마지막으로 모델은 N-best list decoding으로 decode하였다.
아래의 그림은 paper에 실린 그림으로, 문자와 입력 음성간의 할당 (Alignment)를 보여준다.
"how much would a woodchuck chuck" 라는 음성 input에 따른 character alignment를 보여주고 있다. Content based attention mechanism은 첫 번째 문자에 대한 오디오 시퀀스의 시작 위치를 올바르게 식별할 수 있었다고 한다. 생성 된 alignment(그림)은 일반적으로 위치 기반 prior가 없이도 단조로운걸 주장하고 있다.
Content based Attention Mechanism은 문자와 오디오 신호 사이의 명확한 정렬을 만들고 있다. 모든 문자의 output 시간 단계에서 audio 시퀀스에 attention distribution을 기록하여 attention mechanism을 visualization 할 수 있었다고 한다.
이 논문에 쓰여진 2015년 8월 기준으로, 저자는 여러가지 end-to-end trained speech models이 폭발적으로 증가했다고 한다. 그러나 이 모델(
- A. Graves and N. Jaitly, “Towards End-to-End Speech
Recognition with Recurrent Neural Networks,” in International Conference on Machine Learning, 2014.
- Y. Miao, M. Gowayyed, and F. Metze, “EESEN: End-to-End
Speech Recognition using Deep RNN Models and WFSTbased Decoding,” in Http://arxiv.org/abs/1507.08240, 2015.
- D. Bahdanau, J. Chorowski, D. Serdyuk, P. Brakel, and
Y. Bengio, “End-to-end attention-based large vocabulary
speech recognition,” in Http://arxiv.org/abs/1508.04395,
2015.
- A. Hannun, C. Case, J. Casper, B. Catanzaro, G. Diamos, E.
Elsen, R. Prenger, S. Satheesh, S. Sengupta, A. Coates, and
A. Ng, “Deep Speech: Scaling up end-to-end speech recognition,” in Http://arxiv.org/abs/1412.5567, 2014.
- A. Maas, Z. Xie, D. Jurafsky, and A. Ng, “Lexicon-free
conversational speech recognition with neural networks,” in
North American Chapter of the Association for Computational Linguistics, 2015.
)들은 고유의 단점을 갖고 있고, 그 단점을 해결하기 위해 이 논문을 제안했다고 한다.
논문에서 주장하는 이 단점이라 함은, 좋은 정확도를 얻기 위해서는 use of a strong language model during beam search decoding 이라고 표현되어 있따. 즉, 언어 모델 사용은 CTC 목적에 독립적으로 고정되어 훈련되기 때문이다.
CTC는 또한 FST를 사용하여 음소 표적 및 n-gram 언어 모델을 사용하는 종단 간 교육에 적용되었지만, FST에서는 발음 사전과 언어 모델을 사용하기 때문에 LAS와는 다르다.
- 여기에서 FST는 Finite-state Transducer 로서, 한국말로는 유한 상태 변환기이다.
즉, CTC는 end-to-end 음성 인식에서 엄청난 가능성을 보여 주었지만, 1개의 frame의 output은 다른 frame의 출력에 영향을 미치지 않기 때문에 프레임 간 독립성의 가정에 의해 제한된다. 그리하여 CTC는 이 문제를 개선하기 위한 유일한 방법이 강력한 언어 모델을 사용 하는데, LAS의 저자는 이 점을 뽑아서 단점이라고 주장하고 있다.
그렇다면 LAS는?
LAS는 시퀀스-시퀀스: Seq2Seq2 아키텍처를 기반으로하며 위의 단점을 겪지 않는다고 한다. LAS는 CTC의 단점을 해결하기 위해 첫 번째 문자에서 시작하여(sos) Chain Rule Decomposition을 사용하여 input sequence 가 주어진 경우 output sequence를 모델링 한다고 주장하고 있다. 또한 이 end-to-end LAS 모델은 음성 인식 시스템의 모든 측면 - 음향, 발음, 언어 모델 모두 해당 인코딩 - 을 포함한다고 주장한다. 따라서 저자는 LAS가 end-to-end 훈련 시스템이 아니라 end-to-end 모델이 될 수 있다고 주장한다. 굉장히 powerful 하다고 마지막에 주장하고 있다.
5. Conclusion
저자는 Listen, Attend and Spell = LAS를 제안하고 있고, 음향 신호를 직접적으로 문자로 표현해줄 수 있는 모델인 LAS를 제안하고 있다. 이 모델에는 전통적인 음성인식 기법인 HMM(Hidden Markov Model), 언어 모델, 음향, 사전적인 구성 요소가 없이도 음성 인식이 가능한 것을 제안하고 있다. 이 LAS는 end-to-end trained system일 뿐만 아니라, 자체적으로 end-to-end 모델이라고 주장한다. LAS는 Seq2Seq framework를 사용하여 출력 sequence에 대한 조건부 독립 가정을 설정하지 않고 음성 인식이 가능하며, 이것은 CTC, DNN-HMM 및 end-to-end 훈련을 받을 수 있는 다른 모델과는 다르다고 주장한다.(조건 독립)
6. 간단 요약 및 느낀점
- Propose End-to-End Encoder-Decoder Model
- This model can End-to-End model (Not using HMMs, language model, etc)
- Transcribing Speech Utterances to Characters Task
- 14.1% WER w/o dictionary or language model, and 10.3% with language model. The Compare model is State-of-the-art CLDNN-HMM model achieves 8.0%
- 이 논문을 찾아보게 된 건 음성 인식 및 dialect 관련하여 자료를 찾다가 오래되었지만 LAS라는 모델을 기반으로 논문이 발행된 것이 있어서 찾게 되었다. 기존의 음성인식은 CTC에 언어모델을 접합하거나 GMM, HMM을 이용하여 하였지만, 이 논문 같은 경우 언어모델을 사용하지 않고도 어느정도의 WER를 뽑은 것을 확인할 수 있었다.
- 다음에는 Dialect 인식 및 Attention Mechanism을 이용한 접근 법에 대해 찾아 볼 계획이다.
- 대학원생의 주관적인 생각이 들어있으므로 관련 논문에 대해 잘못된 부분이나 comment는 언제나 환영합니다.
최근 Andrew Ng의 Baidu AI 팀은 텍스트를 음성으로 변환하기위한 새로운 딥 러닝 기반 시스템에 관한 인상적인 논문을 발표했다.
1. 분명히 Baidu의 결과는 MacOS의 프로덕션 TTS 시스템과 비교할 때 자연스럽게 들린다. 위의 내용은 한 가지 큰 경고로 볼 수있는데, Baidu의 results 샘플들은 그 문장이 훨씬 더 인간이 말하는 것과 가까운 품질을 제공하고, 이 샘플들을 누군가는 또 Groundtruth의 training sample로 사용할 수 있다는 것이다. 또한 Baidu 샘플은 빈도 및 기간 데이터에도 액세스 할 수 있다.
그러나 출력의 품질을 넘어서 이 논문이 새로운 지평을 열었던 몇 가지 주요 방법은 바로 Deep Voice는 모든 TTS Pipeline에 Deep learning을 사용하였다는 것이다.
이전의 TTS 시스템은 파이프 라인의 여러 구성 요소에 딥 러닝을 사용했지만이 논문 이전에는 모든 주요 구성 요소를 신경망으로 대체하기 위한 연구는 없었다.
2. 딥 러닝을 사용하여 저자는 기존 파이프 라인에 비해 많은 기능 처리 및 엔지니어링을 피할 수 있었다. (이 말은 기존의 머신러닝의 HMM-State 등 복잡한 계산을 피하였다는 뜻으로 해석 됨) 이는 Deep Voice를 훨씬 더 일반적으로 만들어 다른 문제 영역에 적용 할 수 있다. 실제로 Deep Paper는 아래 논문의 저자가 설명한 것처럼 기존 시스템에서 (머신러닝, HMM-STATE, Kaldi 등) 몇 주 정도 걸리는 시간을 이 논문에서는 몇 시간 만에 다시 조정할 수 있었다고 한다.
기존의 TTS 시스템에서 [재교육]은 며칠에서 몇 주까지의 튜닝이 필요하지만 Deep Voice를 사용하면 몇 시간만에 모델 훈련을 끝내어 서비스가 가능하다.
3. 최신 기술에 비해 매우 빠르다.
이 논문의 저자는 인간이 말하는 것과 같은 오디오 합성에 관한 DeepMind의 주요 논문 인 WaveNet보다 400 배 빠른 속도를 달성한다고 주장하였다. 특히 그들은 다음과 밝혔는데,
프로덕션 준비 시스템을 만드는 데 중점을두기 때문에 evaluation을 위해 모델을 실시간으로 실행해야 했었다. Deep Voice는 1 초 단위로 오디오를 합성 할 수 있으며 합성 속도와 오디오 품질간에 조정 가능한 균형을 제공할 수 있다. 반대로 WaveNet의 이전 결과는 1 초의 오디오를 합성하는 데 몇 분의 런타임이 필요하다. (그러므로 우리 것이 훨씬 빠르다.)
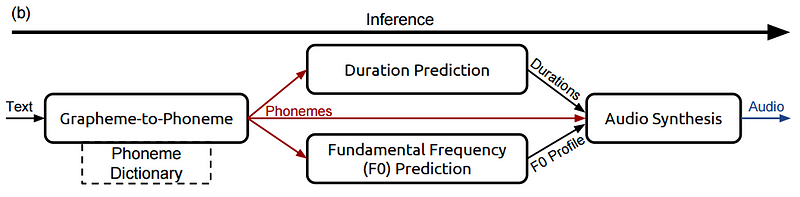
먼저 Deep Voice가 어떻게 문장의 예를 들어 높은 수준에서 음성으로 변환하는지 살펴 보겠다. 이것을 추론 파이프 라인이라고 한다.
추론 파이프 라인 — 새로운 텍스트를 음성으로 변환
이제 Deep Voice에서 간단한 문장을 가져 와서들을 수있는 오디오로 변환하는 방법을 개략적으로 살펴 보겠다. 파이프 라인은 다음과 같이 아키텍처를 갖는다.
이제이 파이프 라인을 단계별로 살펴보고이 조각들이 무엇인지, 어떻게 결합되는지 이해해본다. 특히, 다음 문구를 추적하여 Deep Voice가 어떻게 처리되는지 확인한다.
It was early spring.
1 단계 : 그래 핀 (텍스트)을 음소로 변환
영어와 같은 언어는 음성이 아닌 점에서 독특하다. 예를 들어, 아래를 확인해보자.
1. though (like o in go)
2. through (like oo in too)
3. cough (like off in offer)
4. rough (like uff in suffer)
철자가 같은데도 발음이 어떻게 다른지 주목해야 된다. 바이두의 TTS 시스템이 철자를 주 입력으로 사용했다면,“though”와 “rough”가 같은 접미사를 갖지만 왜 그렇게 다르게 발음해야 하는지를 조정하려는 문제가 불가피하게 발생한다. 따라서 발음에 대한 자세한 정보를 나타내는 약간 다른 단어 표현을 사용해야한다.
이것이 바로 음소 (phoneme)이다. 음소는 우리가 만드는 소리의 다른 단위이다. 그것들을 함께 사용하면 거의 모든 단어에 대한 발음을 재현 할 수 있다. 다음은 CMU의 음소 사전에서 수정 된 음소로 분리 된 단어의 몇 가지 예다.
White Room — [W, AY1, T, ., R, UW1, M, .]
Crossroads — [K, R, AO1, S, R, OW2, D, Z, .]
음소 옆에있는 1, 2 등의 숫자는 발음의 스트레스가 있어야하는 위치를 나타내며, 또한 마침표는 발음에서 빈 공간을 나타낸다. (Slience, End 부분)
따라서 Deep Voice의 첫 단계는 이와 같은 간단한 음소 사전을 사용하여 모든 문장을 음소 표현으로 간단히 변환하는 것이다. 즉 이러한 작업을, Grapheme to Phoneme (G2P) 라고 부른다.
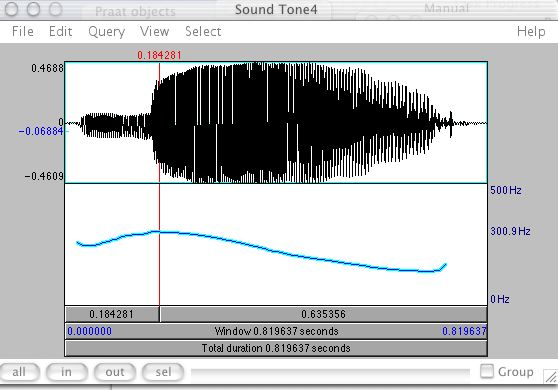
The fundamental frequency (the blue line) is the lowest frequency the vocal cords produce during the voiced phoneme (think of it as the shape of the waveform). We’ll aim to predict this for each phoneme.
또한 각 음소의 톤과 억양을 예측하여 가능한 한 사람이 들리도록 만들려고 한다. 여러 가지면에서 이것은 동일한 사운드가 톤과 악센트에 따라 완전히 다른 의미를 가질 수 있는 만다린(중국)과 같은 언어에서 특히 중요하다. 각 음소의 기본 주파수를 예측할 수 있다면, 이 작업을 수행하는 데 도움이 된다. 주파수는 시스템이 음소가 발음 되어야 하는 대략적인 피치 또는 톤을 정확하게 알려주는 기능을 한다.
또한 일부 음소는 전혀 소리가 나지 않는데, 이것은 성대의 진동없이 발음 된다는 것을 의미한다. 예를 들어, 소리 "ssss"및 "zzzz"를 말하고 전자가 성대에서 진동을 일으키지 않는 경우 (음성 없음) 가 존재한다.
기본 주파수 예측은 이것을 고려하여 음소가 언제 울려야 하는지 그리고 그렇지 않아야 하는지를 예측한다.
Output - [IH1 (140hz), T (142hz), . (Not voiced), …]
Step 3: Audio Synthesis
In the final step, we’ll combine phonemes, durations, and the fundamental frequencies (fO profile) to create real audio.
음성을 만드는 마지막 단계는 음소, 지속 시간 및 주파수를 결합하여 사운드를 출력하는 것이다. Deep Voice는 수정 된 버전의 DeepMind WaveNet을 사용하여 이 단계를 수행하였다. WaveNet의 기본 아키텍처를 이해하려면 해당 논문을 찾아보자. Autoregressive한 vocoder의 역할을 맡고 있다.
높은 수준에서 WaveNet은 raw audio를 생성하여 다양한 악센트, 감정, 호흡 및 기타 인간의 말의 기본 부분을 포함한 모든 유형의 사운드를 생성 할 수 있다. 또한 WaveNet은 이 한 단계 더 나아가 음악을 생성 할 수도 있다.
이 논문에서, Baidu 팀은 특히 고주파 입력을 위해 구현을 최적화하여 WaveNet을 수정하였다. 따라서 WaveNet에서 새로운 오디오를 생성하는데 몇 분이 걸리는 경우 Baidu의 수정 된 WaveNet은 Deep Voice의 저자가 설명하는 것처럼 1 초도 채 걸리지 않을 수 있다고 주장한다.
Deep Voice는 1 초 단위로 오디오를 합성 할 수 있으며 합성 속도와 오디오 품질간에 조정 가능한 균형을 제공한다. (하지만 블랙박스겠지...) 반대로 WaveNet의 이전 결과는 1 초의 오디오를 합성하는 데 몇 분의 시간이 소요될 수 밖에 없다.
Summary
이 3 단계를 통해 Deep Voice가 간단한 텍스트를 가져 와서 오디오 표현을 발견하는 방법을 살펴보았다. 단계를 한 번 더 요약하면 다음과 같다.