본 논문의 제목은 wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations [1] 이며, vq-wav2vec 기법에 Transformer [2] 네트워크 사용 및 BERT의 masking을 audio에 적용한 논문이다.
Overview
- BERT [3]의 Masked Language Modeling의 기법인 MLM을 raw speech에 사용
- Self-supervised learning
- 단 10분의 labelled 음성 (40개)으로 fine-tuning하여 LibriSpeech의 clean 5.7 / noisy 10.1 Word error rate 기록
Proposed
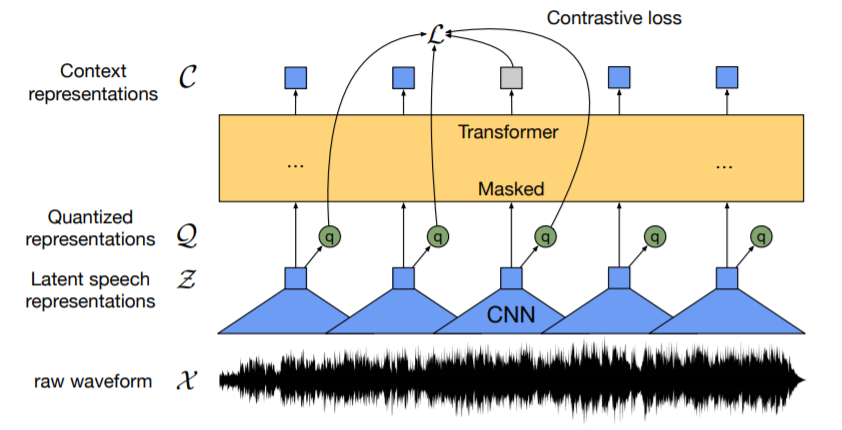
1. Feature Encoder $f$
- 다중 CNN 기반의 encoder $f:\mathcal{X}$⟼$\mathcal{Z}$
- 여기에서 $\mathcal{X}$ 는 입력 raw audio이며, ouptut은 latent speech representation인 $z_1,...,z_T$가 $T$ time-steps 만큼 있음
2. Quantization module
- Encoder의 output feature는 양자화 모듈 $\mathcal{Z}$⟼$\mathcal{Q}$을 사용하여 $q_t$로 이산화 됨
- Target의 representation을 self-supervised objective 사용

- Feature Encoder output $z$는 $I$ $\in$$R^{G*V}$ logit에 매핑되며, 그룹 $G$에 대한 $v$번째 codebook 항목을 선택하는 확률은 위의 식과 같음
- Codebook의 word $i$는 $i=$argmax$_jp_{g,j}$에 의해 선택됨
- Backpropagation에서는 Gumbel-Softmax [4] 출력의 실제 gradient가 사용됨
3. Context network (Transformer)
- Transformer network에 $\mathcal{Z}$가 입력됨: $g:\mathcal{Z}$⟼$\mathcal{C}$
- 전체 시퀀스로부터 representation $c_1,...,c_T$를 정보를 capturing 함
3.1 Masking
- 전체 오디오 구간 중 6.5를 randomly choice
- 선택된 $z_t$에서 $z_{t+10}$만큼 masking
- 전체 $T$의 49%가 평균 span length인 299ms로 마스킹 됨
Objective and loss
1) BERT의 masked language modeling (MLM)과 유사하게 latent speech의 일부분을 masking하며, 모델은 quantized latent audio representation을 맞추는 방식으로 트레이닝이 진행됨
- 이렇게 학습한 후 labeled 된 데이터로 fine-tuning 진행
- 마스킹 된 representation에 대한 quantized latent speech representation 식별하는 식은 아래와 같음
$\mathcal{L}$=$\mathcal{L_m}+\alpha\mathcal{L_d}$
2) $\mathcal{L_M}$
- 모델이 실제 quantized 된 latent speech representation 및 K distractor 식별해야하는 대비 손실 Lm.
- Distractors는 동일한 발화의 다른 마스킹 된 시간 단계에서 균일하게 샘플링 됨
- 마스킹 된 시간 단계 $t$를 중심으로 컨텍스트 네트워크 출력 $c_t$가 주어지면, 모델은 $q_t$ 및 $K$개의 distractor를 포함하는 $K+1$ 양자화 된 후보 representation ~$q\in{Q_t}$ 세트에서, 실제 양자화 된 잠재 음성 표현 $q_t$를 식별함
- Distractors는 동일한 발화의 다른 마스킹 된 시간 단계에서 균일하게 샘플링되며, $K = $distractor, 즉 방해 요소임
$\mathcal{L_M}$ = -log$\frac{\exp(sim(c_t,q_t)/\mathcal{k})}{\Sigma\bar{q}~Q_t\exp(sim(c_t,\bar{q})/\mathcal{k})}$
- 여기에서 $sim(a,b)$ = $a^Tb/||a||b||$ 임. 즉 식에서는 $c_t$와 $q_t$의 유사성
3) $\mathcal{L_d}$
- 각 $G$코드북에서 $V$항목의 동일한 사용을 권장하기 위한 로스 함수이며, 이를 위해 Contrastive loss는 코드북에 의존하여 positive 인 예제와 negative 예제를 모두 나타냄
- 즉, 모델이 코드북 항목을 똑같이 자주 사용하도록 장려하는 다양성 손실 $\mathcal{L_d}$임
- 저자는 speech segmentation의 배치에 걸쳐 각 codebook에 대한 평균 소프트 맥스 분포 $l$의 엔트로피를 최대화함으로써 각 $G$코드북에서 $V$항목의 동일한 사용을 권장
$\mathcal{L_d}=\frac{1}{GV}\Sigma_{g=1}^G-H(\bar{p_g})$
==> $\frac{1}{GV}\Sigma_{g=1}^G\Sigma_{v=1}^V\bar{p}_{g,v}\log\bar{p}_{g,v}$
- $V$ 항목 $e\in\frac{{R^{Vxd}}}{G}$ 가 있는 $G$ 코드북 또는 그룹이 주어지면, 각 코드북에서 하나의 항목을 선택한 뒤, 결과 벡터 $e_1$을 연결함
Downstream task
- 저자는 작업의 어휘를 나타내는 $𝐶$ 클래스에 컨텍스트 네트워크 (Transformer) 위에 무작위로 초기화 된 linear proejction을 추가함
- Librispeech의 경우 character target을 위한 29개의 토큰과 word 경계 토큰이 있음
- CTC [5] 손실을 최소화하여 모델을 최적화함
Results
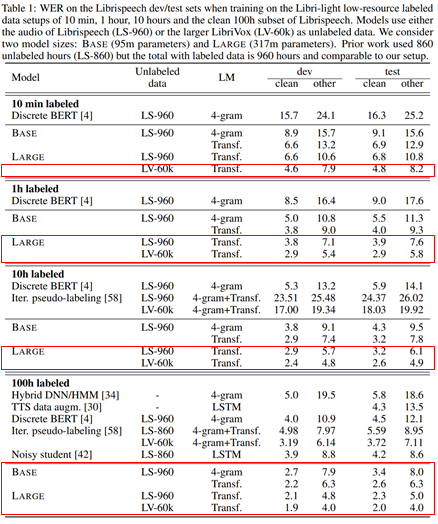
- 10분 fine-tuning의 경우 clean 4.8%, noisy 8.2%의 WER 달성
- 1시간 fine-tuning의 경우 clean 2.9%, noisy 5.8%의 WER 달성
- 10시간 fine-tuning의 경우 clean 2.6%, noisy 4.9%의 WER 달성
- 100시간 fine-tuning의 경우 clean 2.0%, noisy 4.0%의 WER 달성
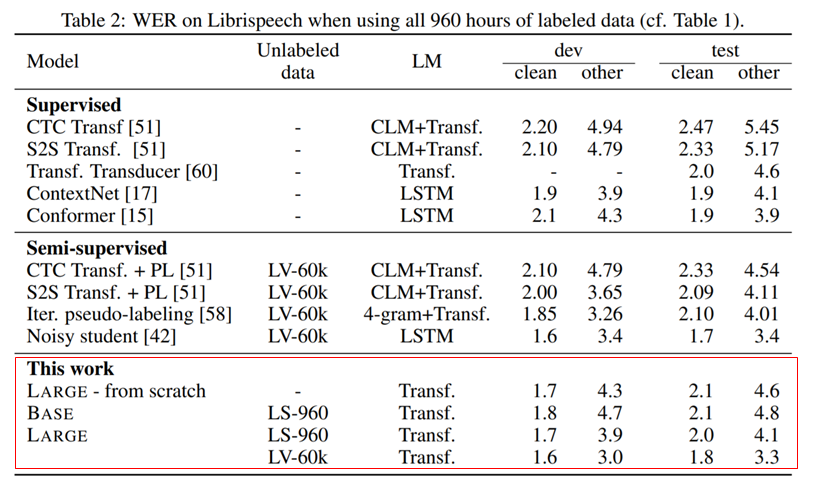
- 960시간 전체 다 사용시, clean 1.8% noisy 3.3%의 WER 달성
[1] Baevski, Alexei, et al. "wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations." Advances in Neural Information Processing Systems 33 (2020).
[2] Vaswani, Ashish, et al. "Attention is All you Need." NIPS. 2017.
[3] Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018).
[4] Jang, Eric, Shixiang Gu, and Ben Poole. "Categorical reparameterization with gumbel-softmax." arXiv preprint arXiv:1611.01144 (2016).
[5] Graves, Alex, et al. "Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks." Proceedings of the 23rd international conference on Machine learning. 2006.
'Paper Review > Unsupervised, Self & Semi-supervised' 카테고리의 다른 글
| Mockingjay: Unsupervised speech representation learning with deep bidirectional transformer encoders 리뷰 (0) | 2021.04.25 |
|---|---|
| DeCoAR: Deep Contextualized Acoustic Representations For Semi-Supervised Speech Recognition 리뷰 (0) | 2021.04.25 |
| vq-wav2vec 리뷰 (2) | 2021.04.11 |
| Gumbel-Softmax 리뷰 (4) | 2021.04.11 |
| VQ-VAE 리뷰 (0) | 2021.04.11 |