바이두 Deep Voice Review
이 논문의 일부 아이디어는 매우 직관적이다. Text to Speech Systems에 딥 러닝을 적용하는 Baidu의 Deep Voice를 다룬다.

Arxiv Link: https://arxiv.org/abs/1702.07825
기관 : 바이두 리서치
최근 Andrew Ng의 Baidu AI 팀은 텍스트를 음성으로 변환하기위한 새로운 딥 러닝 기반 시스템에 관한 인상적인 논문을 발표했다.
1. 분명히 Baidu의 결과는 MacOS의 프로덕션 TTS 시스템과 비교할 때 자연스럽게 들린다. 위의 내용은 한 가지 큰 경고로 볼 수있는데, Baidu의 results 샘플들은 그 문장이 훨씬 더 인간이 말하는 것과 가까운 품질을 제공하고, 이 샘플들을 누군가는 또 Groundtruth의 training sample로 사용할 수 있다는 것이다. 또한 Baidu 샘플은 빈도 및 기간 데이터에도 액세스 할 수 있다.
그러나 출력의 품질을 넘어서 이 논문이 새로운 지평을 열었던 몇 가지 주요 방법은 바로 Deep Voice는 모든 TTS Pipeline에 Deep learning을 사용하였다는 것이다.
이전의 TTS 시스템은 파이프 라인의 여러 구성 요소에 딥 러닝을 사용했지만이 논문 이전에는 모든 주요 구성 요소를 신경망으로 대체하기 위한 연구는 없었다.
2. 딥 러닝을 사용하여 저자는 기존 파이프 라인에 비해 많은 기능 처리 및 엔지니어링을 피할 수 있었다. (이 말은 기존의 머신러닝의 HMM-State 등 복잡한 계산을 피하였다는 뜻으로 해석 됨) 이는 Deep Voice를 훨씬 더 일반적으로 만들어 다른 문제 영역에 적용 할 수 있다. 실제로 Deep Paper는 아래 논문의 저자가 설명한 것처럼 기존 시스템에서 (머신러닝, HMM-STATE, Kaldi 등) 몇 주 정도 걸리는 시간을 이 논문에서는 몇 시간 만에 다시 조정할 수 있었다고 한다.
기존의 TTS 시스템에서 [재교육]은 며칠에서 몇 주까지의 튜닝이 필요하지만 Deep Voice를 사용하면 몇 시간만에 모델 훈련을 끝내어 서비스가 가능하다.
3. 최신 기술에 비해 매우 빠르다.
이 논문의 저자는 인간이 말하는 것과 같은 오디오 합성에 관한 DeepMind의 주요 논문 인 WaveNet보다 400 배 빠른 속도를 달성한다고 주장하였다. 특히 그들은 다음과 밝혔는데,
프로덕션 준비 시스템을 만드는 데 중점을두기 때문에 evaluation을 위해 모델을 실시간으로 실행해야 했었다. Deep Voice는 1 초 단위로 오디오를 합성 할 수 있으며 합성 속도와 오디오 품질간에 조정 가능한 균형을 제공할 수 있다. 반대로 WaveNet의 이전 결과는 1 초의 오디오를 합성하는 데 몇 분의 런타임이 필요하다. (그러므로 우리 것이 훨씬 빠르다.)
먼저 Deep Voice가 어떻게 문장의 예를 들어 높은 수준에서 음성으로 변환하는지 살펴 보겠다. 이것을 추론 파이프 라인이라고 한다.
추론 파이프 라인 — 새로운 텍스트를 음성으로 변환
이제 Deep Voice에서 간단한 문장을 가져 와서들을 수있는 오디오로 변환하는 방법을 개략적으로 살펴 보겠다. 파이프 라인은 다음과 같이 아키텍처를 갖는다.
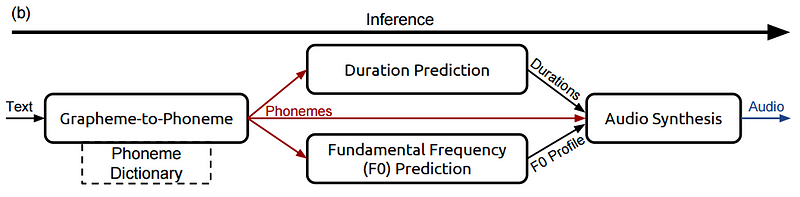
이제이 파이프 라인을 단계별로 살펴보고이 조각들이 무엇인지, 어떻게 결합되는지 이해해본다. 특히, 다음 문구를 추적하여 Deep Voice가 어떻게 처리되는지 확인한다.
It was early spring.
1 단계 : 그래 핀 (텍스트)을 음소로 변환
영어와 같은 언어는 음성이 아닌 점에서 독특하다. 예를 들어, 아래를 확인해보자.
1. though (like o in go)
2. through (like oo in too)
3. cough (like off in offer)
4. rough (like uff in suffer)
철자가 같은데도 발음이 어떻게 다른지 주목해야 된다. 바이두의 TTS 시스템이 철자를 주 입력으로 사용했다면,“though”와 “rough”가 같은 접미사를 갖지만 왜 그렇게 다르게 발음해야 하는지를 조정하려는 문제가 불가피하게 발생한다. 따라서 발음에 대한 자세한 정보를 나타내는 약간 다른 단어 표현을 사용해야한다.
이것이 바로 음소 (phoneme)이다. 음소는 우리가 만드는 소리의 다른 단위이다. 그것들을 함께 사용하면 거의 모든 단어에 대한 발음을 재현 할 수 있다. 다음은 CMU의 음소 사전에서 수정 된 음소로 분리 된 단어의 몇 가지 예다.
- White Room — [W, AY1, T, ., R, UW1, M, .]
- Crossroads — [K, R, AO1, S, R, OW2, D, Z, .]
음소 옆에있는 1, 2 등의 숫자는 발음의 스트레스가 있어야하는 위치를 나타내며, 또한 마침표는 발음에서 빈 공간을 나타낸다. (Slience, End 부분)
따라서 Deep Voice의 첫 단계는 이와 같은 간단한 음소 사전을 사용하여 모든 문장을 음소 표현으로 간단히 변환하는 것이다. 즉 이러한 작업을, Grapheme to Phoneme (G2P) 라고 부른다.
예를 들어, 첫 번째 단계에서 Deep Voice에는 다음과 같은 입력 및 출력이 있다.
- Input - “It was early spring”
- Output - [IH1, T, ., W, AA1, Z, ., ER1, L, IY0, ., S, P, R, IH1, NG, .]
Step 2, Part 1: Duration Prediction
음소가 생겼으니, 말하면서이 음소를 얼마나 오래 참 아야하는지 추정해야한다. 음소가 문맥에 따라 더 길고 짧게 유지되어야하기 때문에 이것은 다시 흥미로운 문제이다. 음소“AH N”을 둘러싼 다음 예제를 보자.
- Unforgettable
- Fun
명백히“AH N”은 첫 번째 경우보다 두 번째 경우보다 훨씬 길어야하며,이를 위해 시스템을 훈련시킬 수 있다. 특히, 바이두는 각각의 음소를 취하여 얼마나 오래 (초) 보유 할 것인지 예측한다. 이 단계에서 예제 문장은 다음과 같다.
- Input - [IH1, T, ., W, AA1, Z, ., ER1, L, IY0, ., S, P, R, IH1, NG, .]
- Output - [IH1 (0.1s), T (0.05s), . (0.01s), … ]
Step 2, Part 2: Fundamental Frequency Prediction
또한 각 음소의 톤과 억양을 예측하여 가능한 한 사람이 들리도록 만들려고 한다. 여러 가지면에서 이것은 동일한 사운드가 톤과 악센트에 따라 완전히 다른 의미를 가질 수 있는 만다린(중국)과 같은 언어에서 특히 중요하다. 각 음소의 기본 주파수를 예측할 수 있다면, 이 작업을 수행하는 데 도움이 된다. 주파수는 시스템이 음소가 발음 되어야 하는 대략적인 피치 또는 톤을 정확하게 알려주는 기능을 한다.
또한 일부 음소는 전혀 소리가 나지 않는데, 이것은 성대의 진동없이 발음 된다는 것을 의미한다. 예를 들어, 소리 "ssss"및 "zzzz"를 말하고 전자가 성대에서 진동을 일으키지 않는 경우 (음성 없음) 가 존재한다.
기본 주파수 예측은 이것을 고려하여 음소가 언제 울려야 하는지 그리고 그렇지 않아야 하는지를 예측한다.
이 단계에서 예제 문장은 다음과 같다.
- Input - [IH1, T, ., W, AA1, Z, ., ER1, L, IY0, ., S, P, R, IH1, NG, .]
- Output - [IH1 (140hz), T (142hz), . (Not voiced), …]
Step 3: Audio Synthesis

음성을 만드는 마지막 단계는 음소, 지속 시간 및 주파수를 결합하여 사운드를 출력하는 것이다. Deep Voice는 수정 된 버전의 DeepMind WaveNet을 사용하여 이 단계를 수행하였다. WaveNet의 기본 아키텍처를 이해하려면 해당 논문을 찾아보자. Autoregressive한 vocoder의 역할을 맡고 있다.

높은 수준에서 WaveNet은 raw audio를 생성하여 다양한 악센트, 감정, 호흡 및 기타 인간의 말의 기본 부분을 포함한 모든 유형의 사운드를 생성 할 수 있다. 또한 WaveNet은 이 한 단계 더 나아가 음악을 생성 할 수도 있다.
이 논문에서, Baidu 팀은 특히 고주파 입력을 위해 구현을 최적화하여 WaveNet을 수정하였다. 따라서 WaveNet에서 새로운 오디오를 생성하는데 몇 분이 걸리는 경우 Baidu의 수정 된 WaveNet은 Deep Voice의 저자가 설명하는 것처럼 1 초도 채 걸리지 않을 수 있다고 주장한다.
Deep Voice는 1 초 단위로 오디오를 합성 할 수 있으며 합성 속도와 오디오 품질간에 조정 가능한 균형을 제공한다. (하지만 블랙박스겠지...) 반대로 WaveNet의 이전 결과는 1 초의 오디오를 합성하는 데 몇 분의 시간이 소요될 수 밖에 없다.
Summary
이 3 단계를 통해 Deep Voice가 간단한 텍스트를 가져 와서 오디오 표현을 발견하는 방법을 살펴보았다. 단계를 한 번 더 요약하면 다음과 같다.
- 텍스트를 음소로 변환 (G2P 이용) “It was early spring”
- [IH1, T, ., W, AA1, Z, ., ER1, L, IY0, ., S, P, R, IH1, NG, .]
2. 각 음소의 지속 시간과 빈도 예측
- [IH1, T, ., W, AA1, Z, ., ER1, L, IY0, ., S, P, R, IH1, NG, .] -> [IH1 (140hz, 0.5s), T (142hz, 0.1s), . (Not voiced, 0.2s), W (140hz, 0.3s),…]
3. 음소, 지속 시간 및 주파수를 결합하여 텍스트를 나타내는 음파 출력
- [IH1 (140hz, 0.5s), T (142hz, 0.1s), . (Not voiced, 0.2s), W (140hz, 0.3s),…] -> Audio
'Paper Review > Speech Recognition' 카테고리의 다른 글
| Self-Training for End-to-End Speech Recognition 리뷰 (0) | 2021.07.04 |
|---|---|
| Sequence-to-sequence speech recognition with time-depth separable convolutions 리뷰 (0) | 2021.07.04 |
| SpecAugment 리뷰 (2) | 2021.01.10 |
| Feature Learning in Deep Neural Networks - A Study on Speech Recognition Tasks (0) | 2021.01.08 |
| Listen, Attend and Spell 리뷰 (0) | 2019.03.19 |